内容:
-
使用刘宇翔切分出来的标题块, 使用之前的OCR方法进行识别
-
初步识别类别包括
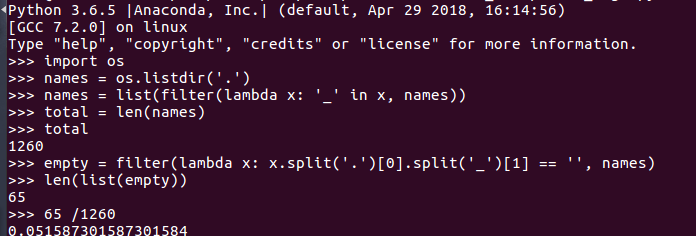
宣判笔录:1260
民事调解书:977
申请书:990
判决书:890
民事裁定书: 958
思路方法:
-
进入290的服务器
ssh -p 290 root@192.168.68.33 -
在/usr/local/src/cnn_universial 下启动服务
python app.py(观察是否需要改动端口,这里的端口是4444) -
使用wget, 写一个脚本,调用OCR的docker
-
OCR识别结果,再使用文字匹配,进行标题分类
-
陈:cnn+inception
- 直接整个图片,端到端,进行分类
-
刘:ssd(特征金字塔思想,目标识别)+text_box+inception
-
标题提取 , 直接分类
-
标题框提取
-
-
识别结果:
| 总数 | OCR识别准确率 | 标题分类准确率 | 识别为空 | |
|---|---|---|---|---|
| 宣判笔录 | 1260 | 90% | 94.7% | 5% |
| 调解书 | 977 | 64%;(80%) | 92.1% | 3.7% |
| 申请书 | 990 | |||
| 裁定书 | 958 | |||
| 判决书 | 890 |
源码:
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
import shutil
import os
import requests
import progressbar as bar
"""
time: 2019/4/1
contain: wget脚本,完成对图片的批量预测
inputs:标题图片
outputs:OCR识别结果,保存在txt中,并且以预测结果命名
"""
def wget_ocr(inputs_path):
files = os.listdir(inputs_path)
# 遍历文件夹下所有内容
for file in files:
# f = open(inputs_path+'/'+file)
urls = os.path.join("http://localhost:4444/")
print(file)
name = requests.get(urls, {'path': os.path.join(inputs_path, file)})
print(name.text)
def ocr_files(input_root, ocr_outputs, target=None ):
# print(os.listdir(input_root))
# match = 0
filenames = list(filter(lambda n: n.split('.')[-1] in ('jpg', 'png', 'jpeg'), os.listdir(input_root)))
match = 0
total = len(filenames)
new_names = list(map(lambda n: n.split('.')[-1], filenames))
url = "http://localhost:4444"
with bar.ProgressBar(max=total) as b:
for idx, filename in enumerate(filenames):
name = requests.get(url, {'path': os.path.join(input_root, filename)}).text.strip()
if name.find(target):
match += 1
new_names[idx] = name+'.'+new_names[idx]
b.update(idx+1)
for idx, (old_name, new_name) in enumerate(zip(filenames, new_names)):
shutil.copyfile(os.path.join(input_root, old_name), os.path.join(ocr_outputs, '..', '%d_'%idx+ new_name))
print(os.path.join(input_root, old_name), '\t->\t', os.path.join(ocr_outputs, '..', '%d_'%idx+ new_name))
return match, total
if __name__ == '__main__':
path = "G:\图像处理\\title_img\\title_img\CDS"
ocr_out = "G:\图像处理\\title_img\\title_img\CDS\\test"
m, t = ocr_files(path, ocr_out,target="裁定书")
print(m/t)
存在问题:
-
噪点,干扰对行的切分
-
识别的准确率,影响最终分类的准确率
-
识别结果为空(原因猜测是因为行切分的时候,单个行,没有切分出来,导致字切分错误)

解决思路:
-
文字太小
字太小之后会使得,噪点就会被放大。

夭津市葡州区人氏法院氏事谢碱(稿)
津市鳍州区人氏蹦氏事调解书(稿)
夭津市到州区人氏璇氏事调碱(稿)
肆璃继战蕊民璃狒怠
夭津市葡州区人氏蕊衅调硝
津市额州区人谜氏骝解!
解决思路:对于标题数据,可能还需要放大字体
-
手写体

语法技巧:
ls > 8.txt: 一个目录下的文件,全部输出到一个txt文件中
wget调用

统计预测为空