
Attention Strategies for Multi-Source Sequence-to-Sequence Learning
-
Jindˇrich Libovick´y and Jindˇrich Helcl. 2017. Attention strategies for multi-source sequence-to-sequence learning. In ACL.
-
提出了flat 和 Hierarchical attention
一、摘要
-
modeling attention in neural multi-source sequence-to-sequence learning remains a relatively unexplored area, despite its usefulness in tasks that incorporate multiple source languages or modalities.
在神经多源序列到序列学习中的建模关注仍然是一个相对未被探索的领域,尽管它在包含多种源语言或模式的任务中很有用。
-
we propose two novel approaches to combine the outputs of attention mechanisms over each source sequence, flat and hierarchical.
我们提出了两种新的方法来组合每个源序列上的注意机制的输出,平面和层次。
-
we compare the proposed methods with existing techniques and present results of systematic evaluation of those methods on the wmt16 multimodal translation and automatic post-editing tasks
我们将所提出的方法与现有的技术进行了比较,并给出了对wmt 16多模式翻译和自动后编辑任务进行系统评价的结果。
-
we show that the proposed methods achieve competitive results on both tasks
结果表明,所提出的方法在这两种任务上都取得了较好的竞争效果。
二、模型
2.1 贡献
-
in this work, we focus on a special case of s2s learning with multiple input sequences of possibly different modalities and a single output-generating recurrent decoder
在本工作中,我们重点研究了一种特殊情况,即S2S学习具有可能具有不同输入序列的多个输入序列,并且具有单个输出产生的循环译码器。
-
we explore various strategies the decoder can employ to attend to the hidden states of the individual encoders
我们探索解码器可以使用的各种策略来处理单个编码器的隐藏状态。
-
we propose two interpretable attention strategies that take into account the roles of the individual source sequences explicitly—flat and hierarchical attention combination
我们提出了两种可解释的注意策略,其中明确地考虑了单个源序列的作用-平面和层次的注意组合。
三、实验
3.1 数据
-
MMT
-
APE
3.2 公式模型详解


3.3 Flat Attention Combination
-
flat attention combination projects the hidden states of all encoders into a shared space and then computes an arbitrary distribution over the projections
平面注意力组合将所有编码器的隐藏状态投影到共享空间中,然后计算投影上的任意分布。



3.4 Hierarchical Attention Combination
-
上下文向量独立地进行计算
-
step1: 按照公式3,独立计算每个context vector
-
step2: 按照公式8,将上下文向量映射到一个common space, 通过公式9计算另一个attention distribution

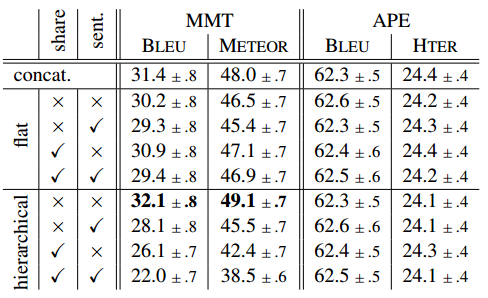
3.5 实验结果
3.6 开源资源
-
The models were implemented using the Neural Monkey sequence-to-sequence learning toolkit (Helcl and Libovicky, 2017). ´ 12
- 1http://github.com/ufal/neuralmonkey
- 2The trained models can be downloaded from http://ufallab.ms.mff.cuni.cz/˜libovicky/acl2017_att_models/




