
一、策略模式
参考网址1:http://www.runoob.com/design-pattern/strategy-pattern.html
策略模式包含如下角色:
- Context: 环境类
- Strategy: 抽象策略类
- ConcreteStrategy: 具体策略类
- ConcreteStrategy: 具体策略类
参考网址2:https://blog.csdn.net/zhengzhb/article/details/7609670
定义:定义一组算法,将每个算法都封装起来,并且使他们之间可以互换。
类型:行为类模式
类图:
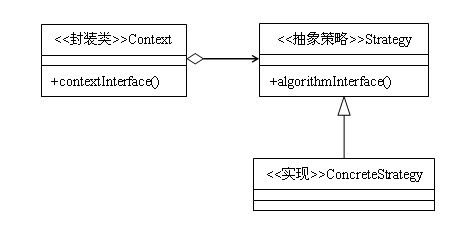
策略模式是对算法的封装,把一系列的算法分别封装到对应的类中,并且这些类实现相同的接口,相互之间可以替换。在前面说过的行为类模式中,有一种模式也是关注对算法的封装——模版方法模式,对照类图可以看到,策略模式与模版方法模式的区别仅仅是多了一个单独的封装类Context,它与模版方法模式的区别在于:在模版方法模式中,调用算法的主体在抽象的父类中,而在策略模式中,调用算法的主体则是封装到了封装类Context中,抽象策略Strategy一般是一个接口,目的只是为了定义规范,里面一般不包含逻辑。其实,这只是通用实现,而在实际编程中,因为各个具体策略实现类之间难免存在一些相同的逻辑,为了避免重复的代码,我们常常使用抽象类来担任Strategy的角色,在里面封装公共的代码,因此,在很多应用的场景中,在策略模式中一般会看到模版方法模式的影子。
策略模式的结构
- 封装类:也叫上下文,对策略进行二次封装,目的是避免高层模块对策略的直接调用。
- 抽象策略:通常情况下为一个接口,当各个实现类中存在着重复的逻辑时,则使用抽象类来封装这部分公共的代码,此时,策略模式看上去更像是模版方法模式。
- 具体策略:具体策略角色通常由一组封装了算法的类来担任,这些类之间可以根据需要自由替换。
策略模式代码实现
interface IStrategy {
public void doSomething();
}
class ConcreteStrategy1 implements IStrategy {
public void doSomething() {
System.out.println("具体策略1");
}
}
class ConcreteStrategy2 implements IStrategy {
public void doSomething() {
System.out.println("具体策略2");
}
}
class Context {
private IStrategy strategy;
public Context(IStrategy strategy){
this.strategy = strategy;
}
public void execute(){
strategy.doSomething();
}
}
public class Client {
public static void main(String[] args){
Context context;
System.out.println("-----执行策略1-----");
context = new Context(new ConcreteStrategy1());
context.execute();
System.out.println("-----执行策略2-----");
context = new Context(new ConcreteStrategy2());
context.execute();
}
}
策略模式的优缺点
策略模式的主要优点有:
- 策略类之间可以自由切换,由于策略类实现自同一个抽象,所以他们之间可以自由切换。
- 易于扩展,增加一个新的策略对策略模式来说非常容易,基本上可以在不改变原有代码的基础上进行扩展。
- 避免使用多重条件,如果不使用策略模式,对于所有的算法,必须使用条件语句进行连接,通过条件判断来决定使用哪一种算法,在上一篇文章中我们已经提到,使用多重条件判断是非常不容易维护的。
策略模式的缺点主要有两个:
- 维护各个策略类会给开发带来额外开销,可能大家在这方面都有经验:一般来说,策略类的数量超过5个,就比较令人头疼了。
- 必须对客户端(调用者)暴露所有的策略类,因为使用哪种策略是由客户端来决定的,因此,客户端应该知道有什么策略,并且了解各种策略之间的区别,否则,后果很严重。例如,有一个排序算法的策略模式,提供了快速排序、冒泡排序、选择排序这三种算法,客户端在使用这些算法之前,是不是先要明白这三种算法的适用情况?再比如,客户端要使用一个容器,有链表实现的,也有数组实现的,客户端是不是也要明白链表和数组有什么区别?就这一点来说是有悖于迪米特法则的。
适用场景
做面向对象设计的,对策略模式一定很熟悉,因为它实质上就是面向对象中的继承和多态,在看完策略模式的通用代码后,我想,即使之前从来没有听说过策略模式,在开发过程中也一定使用过它吧?至少在在以下两种情况下,大家可以考虑使用策略模式,
- 几个类的主要逻辑相同,只在部分逻辑的算法和行为上稍有区别的情况。
- 有几种相似的行为,或者说算法,客户端需要动态地决定使用哪一种,那么可以使用策略模式,将这些算法封装起来供客户端调用。
策略模式是一种简单常用的模式,我们在进行开发的时候,会经常有意无意地使用它,一般来说,策略模式不会单独使用,跟模版方法模式、工厂模式等混合使用的情况比较多。
参考网址3:http://www.runoob.com/design-pattern/strategy-pattern.html
参考网址4:https://blog.csdn.net/carson_ho/article/details/54910374
参考网址5:http://wiki.jikexueyuan.com/project/java-design-pattern/strategy-pattern.html
二、抽象工厂模式
参考网址1:https://blog.csdn.net/zhengzhb/article/details/7359385
定义:为创建一组相关或相互依赖的对象提供一个接口,而且无需指定他们的具体类。
类型:创建类模式
类图:
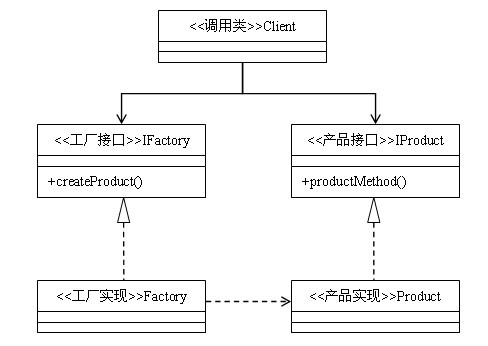
抽象工厂模式与工厂方法模式的区别
抽象工厂模式是工厂方法模式的升级版本,他用来创建一组相关或者相互依赖的对象。他与工厂方法模式的区别就在于,工厂方法模式针对的是一个产品等级结构;而抽象工厂模式则是针对的多个产品等级结构。在编程中,通常一个产品结构,表现为一个接口或者抽象类,也就是说,工厂方法模式提供的所有产品都是衍生自同一个接口或抽象类,而抽象工厂模式所提供的产品则是衍生自不同的接口或抽象类。
在抽象工厂模式中,有一个产品族的概念:所谓的产品族,是指位于不同产品等级结构中功能相关联的产品组成的家族。抽象工厂模式所提供的一系列产品就组成一个产品族;而工厂方法提供的一系列产品称为一个等级结构。我们依然拿生产汽车的例子来说明他们之间的区别。
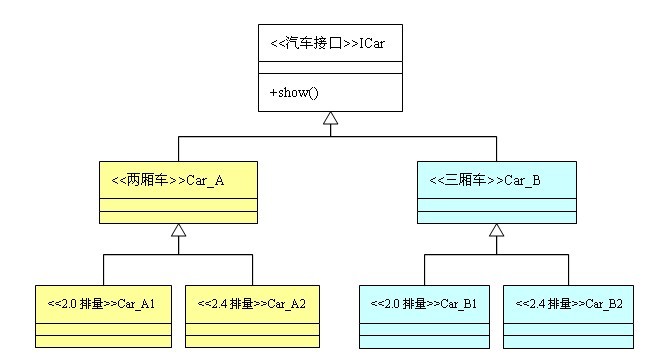
在上面的类图中,两厢车和三厢车称为两个不同的等级结构;而2.0排量车和2.4排量车则称为两个不同的产品族。再具体一点,2.0排量两厢车和2.4排量两厢车属于同一个等级结构,2.0排量三厢车和2.4排量三厢车属于另一个等级结构;而2.0排量两厢车和2.0排量三厢车属于同一个产品族,2.4排量两厢车和2.4排量三厢车属于另一个产品族。
明白了等级结构和产品族的概念,就理解工厂方法模式和抽象工厂模式的区别了,如果工厂的产品全部属于同一个等级结构,则属于工厂方法模式;如果工厂的产品来自多个等级结构,则属于抽象工厂模式。在本例中,如果一个工厂模式提供2.0排量两厢车和2.4排量两厢车,那么他属于工厂方法模式;如果一个工厂模式是提供2.4排量两厢车和2.4排量三厢车两个产品,那么这个工厂模式就是抽象工厂模式,因为他提供的产品是分属两个不同的等级结构。当然,如果一个工厂提供全部四种车型的产品,因为产品分属两个等级结构,他当然也属于抽象工厂模式了。
抽象工厂模式代码
interface IProduct1 {
public void show();
}
interface IProduct2 {
public void show();
}
class Product1 implements IProduct1 {
public void show() {
System.out.println("这是1型产品");
}
}
class Product2 implements IProduct2 {
public void show() {
System.out.println("这是2型产品");
}
}
interface IFactory {
public IProduct1 createProduct1();
public IProduct2 createProduct2();
}
class Factory implements IFactory{
public IProduct1 createProduct1() {
return new Product1();
}
public IProduct2 createProduct2() {
return new Product2();
}
}
public class Client {
public static void main(String[] args){
IFactory factory = new Factory();
factory.createProduct1().show();
factory.createProduct2().show();
}
}
抽象工厂模式的优点
抽象工厂模式除了具有工厂方法模式的优点外,最主要的优点就是可以在类的内部对产品族进行约束。所谓的产品族,一般或多或少的都存在一定的关联,抽象工厂模式就可以在类内部对产品族的关联关系进行定义和描述,而不必专门引入一个新的类来进行管理。
抽象工厂模式的缺点
产品族的扩展将是一件十分费力的事情,假如产品族中需要增加一个新的产品,则几乎所有的工厂类都需要进行修改。所以使用抽象工厂模式时,对产品等级结构的划分是非常重要的。
适用场景
当需要创建的对象是一系列相互关联或相互依赖的产品族时,便可以使用抽象工厂模式。说的更明白一点,就是一个继承体系中,如果存在着多个等级结构(即存在着多个抽象类),并且分属各个等级结构中的实现类之间存在着一定的关联或者约束,就可以使用抽象工厂模式。假如各个等级结构中的实现类之间不存在关联或约束,则使用多个独立的工厂来对产品进行创建,则更合适一点。
总结
无论是简单工厂模式,工厂方法模式,还是抽象工厂模式,他们都属于工厂模式,在形式和特点上也是极为相似的,他们的最终目的都是为了解耦。在使用时,我们不必去在意这个模式到底工厂方法模式还是抽象工厂模式,因为他们之间的演变常常是令人琢磨不透的。经常你会发现,明明使用的工厂方法模式,当新需求来临,稍加修改,加入了一个新方法后,由于类中的产品构成了不同等级结构中的产品族,它就变成抽象工厂模式了;而对于抽象工厂模式,当减少一个方法使的提供的产品不再构成产品族之后,它就演变成了工厂方法模式。
所以,在使用工厂模式时,只需要关心降低耦合度的目的是否达到了。
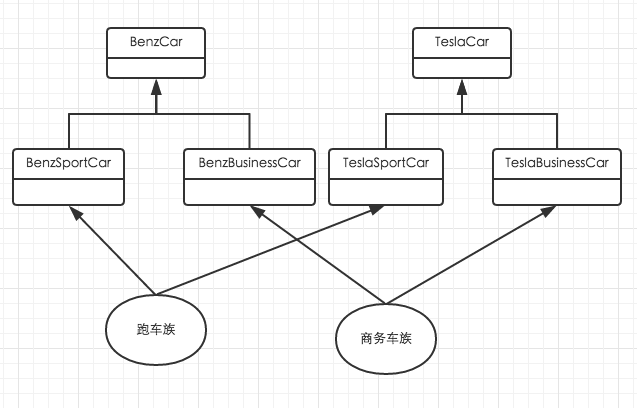
产品族
来认识下什么是产品族: 位于不同产品等级结构中,功能相关的产品组成的家族。如下面的例子,就有两个产品族:跑车族和商务车族。
用途
抽象工厂模式和工厂方法模式一样,都符合开放-封闭原则。但是不同的是,工厂方法模式在增加一个具体产品的时候,都要增加对应的工厂。但是抽象工厂模式只有在新增一个类型的具体产品时才需要新增工厂。也就是说,工厂方法模式的一个工厂只能创建一个具体产品。而抽象工厂模式的一个工厂可以创建属于一类类型的多种具体产品。工厂创建产品的个数介于简单工厂模式和工厂方法模式之间。
在以下情况下可以使用抽象工厂模式:
一个系统不应当依赖于产品类实例如何被创建、组合和表达的细节,这对于所有类型的工厂模式都是重要的。
系统中有多于一个的产品族,而每次只使用其中某一产品族。
属于同一个产品族的产品将在一起使用,这一约束必须在系统的设计中体现出来。
系统提供一个产品类的库,所有的产品以同样的接口出现,从而使客户端不依赖于具体实现。
实现方式
抽象工厂模式包含如下角色:
AbstractFactory(抽象工厂):用于声明生成抽象产品的方法
ConcreteFactory(具体工厂):实现了抽象工厂声明的生成抽象产品的方法,生成一组具体产品,这些产品构成了一个产品族,每一个产品都位于某个产品等级结构中;
AbstractProduct(抽象产品):为每种产品声明接口,在抽象产品中定义了产品的抽象业务方法;
Product(具体产品):定义具体工厂生产的具体产品对象,实现抽象产品接口中定义的业务方法。
本文的例子采用一个汽车代工厂造汽车的例子。假设我们是一家汽车代工厂商,我们负责给奔驰和特斯拉两家公司制造车子。我们简单的把奔驰车理解为需要加油的车,特斯拉为需要充电的车。其中奔驰车中包含跑车和商务车两种,特斯拉同样也包含奔驰车和商务车。
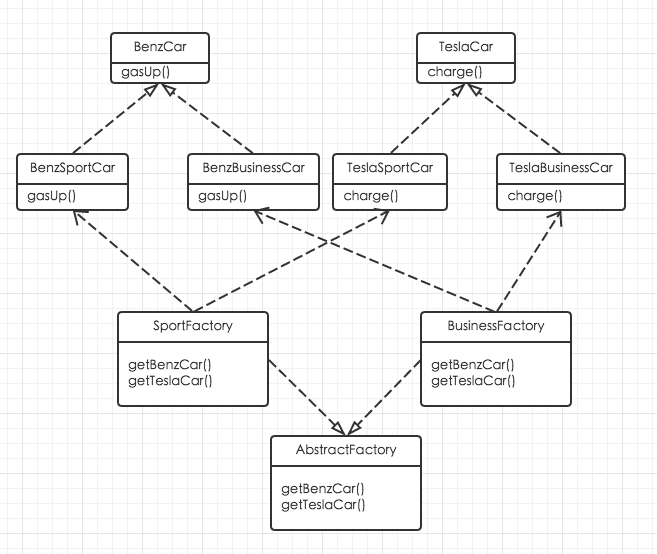
以上场景,我们就可以把跑车和商务车分别对待,对于跑车有单独的工厂创建,商务车也有单独的工厂。这样,以后无论是再帮任何其他厂商造车,只要是跑车或者商务车我们都不需要再引入工厂。同样,如果我们要增加一种其他类型的车,比如越野车,我们也不需要对跑车或者商务车的任何东西做修改。
下面是抽象产品,奔驰车和特斯拉车:
public interface BenzCar {
//加汽油
public void gasUp();
}
public interface TeslaCar {
//充电
public void charge();
}
下面是具体产品,奔驰跑车、奔驰商务车、特斯拉跑车、特斯拉商务车:
public class BenzSportCar implements BenzCar {
public void gasUp() {
System.out.println("给我的奔驰跑车加最好的汽油");
}
}
public class BenzBusinessCar implements BenzCar{
public void gasUp() {
System.out.println("给我的奔驰商务车加一般的汽油");
}
}
public class TeslaSportCar implements TeslaCar {
public void charge() {
System.out.println("给我特斯拉跑车冲满电");
}
}
public class TeslaBusinessCar implements TeslaCar {
public void charge() {
System.out.println("不用给我特斯拉商务车冲满电");
}
}
下面是抽象工厂:
public interface CarFactory {
public BenzCar getBenzCar();
public TeslaCar getTeslaCar();
}
下面是具体工厂:
public class SportCarFactory implements CarFactory {
public BenzCar getBenzCar() {
return new BenzSportCar();
}
public TeslaCar getTeslaCar() {
return new TeslaSportCar();
}
}
public class BusinessCarFactory implements CarFactory {
public BenzCar getBenzCar() {
return new BenzBusinessCar();
}
public TeslaCar getTeslaCar() {
return new TeslaBusinessCar();
}
}
“开闭原则”的倾斜性
“开闭原则”要求系统对扩展开放,对修改封闭,通过扩展达到增强其功能的目的。对于涉及到多个产品族与多个产品等级结构的系统,其功能增强包括两方面:
增加产品族:对于增加新的产品族,工厂方法模式很好的支持了“开闭原则”,对于新增加的产品族,只需要对应增加一个新的具体工厂即可,对已有代码无须做任何修改。
增加新的产品等级结构:对于增加新的产品等级结构,需要修改所有的工厂角色,包括抽象工厂类,在所有的工厂类中都需要增加生产新产品的方法,不能很好地支持“开闭原则”。
抽象工厂模式的这种性质称为“开闭原则”的倾斜性,抽象工厂模式以一种倾斜的方式支持增加新的产品,它为新产品族的增加提供方便,但不能为新的产品等级结构的增加提供这样的方便。
三种工厂模式之间的关系
当抽象工厂模式中每一个具体工厂类只创建一个产品对象,也就是只存在一个产品等级结构时,抽象工厂模式退化成工厂方法模式;
抽象工厂模式与工厂方法模式最大的区别在于,工厂方法模式针对的是一个产品等级结构,而抽象工厂模式则需要面对多个产品等级结构。
当工厂方法模式中抽象工厂与具体工厂合并,提供一个统一的工厂来创建产品对象,并将创建对象的工厂方法设计为静态方法时,工厂方法模式退化成简单工厂模式。
总结
抽象工厂模式提供一个创建一系列相关或相互依赖对象的接口,而无须指定它们具体的类。抽象工厂模式又称为Kit模式,属于对象创建型模式。
抽象工厂模式是所有形式的工厂模式中最为抽象和最具一般性的一种形态。
抽象工厂模式的主要优点是隔离了具体类的生成,使得客户并不需要知道什么被创建,而且每次可以通过具体工厂类创建一个产品族中的多个对象,增加或者替换产品族比较方便,增加新的具体工厂和产品族很方便;主要缺点在于增加新的产品等级结构很复杂,需要修改抽象工厂和所有的具体工厂类,对“开闭原则”的支持呈现倾斜性。
参考网址3:https://design-patterns.readthedocs.io/zh_CN/latest/creational_patterns/abstract_factory.html
参考网址4:https://blog.csdn.net/carson_ho/article/details/54910287
三、单件模式
单件模式(singleton pattern) : 确保一个类只有一个实例, 并提供一个全局访问点.
单价模式包括3个部分: 私有构造器, 静态变量, 静态方法.
参考网址1:https://blog.csdn.net/caroline_wendy/article/details/28595349
/**
* @time 2014.6.5
*/
package singleton;
/**
* @author C.L.Wang
*
*/
public class Singleton {
private static Singleton uniqueInstance; //静态变量
private Singleton() {} //私有构造函数
public static Singleton getInstance() { //静态方法
if (uniqueInstance == null)
uniqueInstance = new Singleton();
return uniqueInstance;
}
}
例子
/**
* @time 2014.6.5
*/
package singleton;
/**
* @author C.L.Wang
*
*/
public class ChocolateBoiler { //巧克力锅炉
private boolean empty;
private boolean boiled;
public static ChocolateBoiler uniqueInstance; //静态变量
private ChocolateBoiler() { //私有构造函数
empty = true;
boiled = false;
}
public static ChocolateBoiler getInstance() { //静态方法
if (uniqueInstance == null)
uniqueInstance = new ChocolateBoiler();
return uniqueInstance;
}
public void fill() { //填满
if (isEmpty()) {
empty = false;
boiled = false;
}
}
public void drain() { //倾倒
if (!isEmpty() && isBoiled())
empty = true;
}
public void boil() { //煮
if (!isEmpty() && !isBoiled()) {
boiled = true;
}
}
public boolean isEmpty() {
return empty;
}
public boolean isBoiled() {
return boiled;
}
}
单件模式,也叫单例模式,可以说是设计模式中最简单的一种。顾名思义,就是创造独一无二的唯一的一个实例化的对象。
为什么要这样做呢?因为有些时候,我们只需要一个对象就够了,太多对象反而会引起不必要的麻烦。比如说,线程池,缓存,打印机,注册表,如果存在多个实例的话,反而会导致许多问题!
引出单例模式
我们通过一个小问题引出单例模式!
- 如何创建一个对象?我们都知道
new MyObject(); - 当我们需要创建与另外一个对象时,只需要再次
new MyObject();即可 - 那么如下这样的代码是正确的么?
public MyClass{
private MyClass() {}
}
- 看过去这是合法的定义,没有什么语法错误。但仔细想想,含有私有构造器的话,只能在MyClass内调用构造器。因为必须有Myclass的实例才能调用构造器,但因为没有其他类可以取得它的实例,所以,我们无法实例化它,这像不像鸡生蛋还是蛋生鸡的问题?哈哈哈
- 为了解决这个问题,取得MyClass类的实例,我们创造一个静态方法
public MyClass{
private MyClass() {}
public static MyClass getInstance() {
return new MyClass();
}
}
- 我们添加了一个静态的类方法,它可以返回一个对象实例,由于他是public,所以外部可以调用他。这实际上就实现了一个简单的单例模式。
经典单例模式的实现
public class Singleton {
private static Singleton uniqueInstance;
private Singleton(){}
public static Singleton getInstance() {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
return uniqueInstance;
}
}
- 这里实现了一个概念,叫延迟实例化(lazy instance)。因为在我们不需要实例的时候,这个实例就永远不会被实例化。
定义单件模式
单件模式的定义: 确保一个类只有一个实例,并提供一个全局访问点。
这定义应该很好理解,我们结合类图说明:

Paste_Image.png
经典单件模式存在的问题
经典单件模式实际中存在这一定的问题,在第一次初始化实例的时候,如果同时有不同的线程访问,那么可能最后不只实例化出一个对象。

Paste_Image.png
如图所示,如果两个线程如图所示的顺序交错执行,那么最后会实例化两个对象! 这就是经典单例模式存在的多线程问题。
参考网址3:https://www.cnblogs.com/libingql/archive/2012/12/01/2797532.html
1. 单件模式简介
1.1 定义
单件模式(Singleton)定义:要求一个类有且仅有一个实例,并且提供了一个全局的访问点,在同一时刻只能被一个线程所访问。
单件模式的特点:
(1)单件类只能有一个实例。
(2)单件类必须自身创建唯一实例。
(3)单件类必须给所有其它对象提供唯一实例。
2、单件模式结构
2.1 结构图

2.2 参与者
单件模式参与者:
◊ Singleton
° 被调用的单件对象;
° 在单件模式中,通常由Instance()或GetInstance()方法负责对象的创建,该方法应保证每个需要(单件)对象的客户端均能访问。
3. 单件模式结构实现
3.1 单件模式实现要点
◊ 单件类有一个私有的无参构造函数,防止被其他类实例化。
◊ 单件类不能被继承,使用sealed修饰。
◊ 单件类使用静态的变量保存单实例的引用。
◊ 单件类使用公有静态方法获取单一实例的引用,如果实例为null即创建一个。
用来创建独一无二的,只能有一个实例的对象的入场券。
单件模式的类图可以说是所有模式的类图中最简单的,事实上,它的类图只有一个类。可是也不是那么简单的。
有一些对象其实我们只需要一个,比方说:线程池(threadpool)、缓存(cache)、对话框、处理偏好设置和注册表(registry)的对象、日志对象、充当打印机、显卡等设备的驱动程序的对象,这类对象只能有一个实例,如果制造出多个实例,就会导致许多问题产生,比如:程序的行为异常、资源使用过量,或者是不一致的结果。
但是难道不能靠程序员之间的约定或是利用全局变量做到?你知道的,利用Java的静态变量就可以做到。
但是有更好的做法,大家应该到乐意接受,单件模式是经得起时间考验的方法,可以确保只有一个实例会被创建,单件模式也给了我们一个全局访问点,和全局变量一样方便,又没有全局变量的缺点。
全局变量的缺点:如果将对象赋值给一个全局变量,那么你必须在程序一开始就创建好对象,万一这个对象非常耗费资源,而程序在这次的执行过程中又一直没用到它,不就是浪费了吗?
问:如何创建一个对象?
答:new MyObject();
问:万一另一个对象想创建MyObject会怎样?可以再次new MyObject吗?
答:是的,当然可以。
问:所以,一旦有一个类,我们是否都能多次地实例化它?
答:如果是公开的类,就可以。
问:如果不是的话,会怎样?
答:如果不是公开尅,只有同一个包内的类可以实例化它,但是仍可以实例化多次。
问:你知道可以这么做吗?
class MyClass{ private MyClass(){} }
答:我认为含有私有的构造器的类不能被实例化。
问:你认为这样如何?
class MyClass{ public static MyClass getInstance(){} }
答:MyClass有一个静态方法,我们可以这样调用这个方法:MyClass.getInstance();
问:假如把这些合在一起”是否”就可以初始化一个MyClass?
class MyClass{ private MyClass(){} public static MyClass getInstance(){ return new MyClass(); } }
剖析经典的单件模式实现
class Singleton{
private static Singleton singleton;
private Singleton(){}
public static Singleton getInstance(){
if(singleton==null){
singleton=new Singleton();
}
return singleton;
}
}
在后面,你会看到这个版本有一些问题。
定义单件模式单件模式确保一个类只有一个实例,并提供一个全局访问点。
单件模式类图:
 书中是有一个列子说明多线程的问题但是太繁琐,这里简单总结下。
上面的例子中如果在判断实例是否为空的那一步有另一个线程进入,就会造成都判断出那个实例都是为空的。那么在另一个线程中也会重复创建新的实例。
处理多线程
只要把getInstance()变成同步{synchronized}方法,多线程灾难几乎就可以轻易地解决了:
书中是有一个列子说明多线程的问题但是太繁琐,这里简单总结下。
上面的例子中如果在判断实例是否为空的那一步有另一个线程进入,就会造成都判断出那个实例都是为空的。那么在另一个线程中也会重复创建新的实例。
处理多线程
只要把getInstance()变成同步{synchronized}方法,多线程灾难几乎就可以轻易地解决了:
class Singleton{
private static Singleton singleton;
private Singleton(){}
public static synchronized Singleton getInstance(){
if(singleton==null){
singleton=new Singleton();
}
return singleton;
}
}
这样是可以的,凡是同步会降低性能,这又是另一个问题。 而且,只有第一次执行此方法时,才真正需要同步,换句话说,一旦设置好singleton变量,就不再需要同步这个方法了,之后每次调用这个方法,同步都是一种累赘。 能够改善多线程吗? 1.如果getInstance()的性能对应用程序不是很关键,就什么都别做。 如果你的程序可以接受getInstance()造成的额外负担,就忘了这件事吧,但是你必须知道,同步一个方法可能造成程序执行效率下降100倍。因此,如果将getInstance()的程序使用在频繁运行的地方,你可能就得重新考虑了。 2.使用”急切”创建实例,而不用延迟实例化的做法 如果应用程序总是创建并使用单间实例,或者在创建和运行时方面的负担不太繁重,你可能想要哦急切创建此单件。如下:
class Singleton{
private static Singleton singleton=new Singleton();
private Singleton(){}
public static Singleton getInstance(){
return singleton;
}
}
利用这个做法,我们依赖jvm在加载这个类时马上创建此唯一的单件实例,JVM保证在任何线程访问singleton静态变量之前,一定先创建此实例。 3用“双重检查加锁”,在 getInstance()中减少使用同步 利用双重检查加锁,首先检查是否实例已经创建了,如果尚未创建,“才”进行同步,这样一来,只有第一次会同步,这正是我们想要的。
class Singleton{
//volatile关键词确保,当singleton变量被初始化成Singleton实例时,多个线程正确处理singleton变量
private volatile static Singleton singleton;
private Singleton(){}
public static Singleton getInstance(){
//如果不存在,就进入同步区块
if (singleton==null){
//只有第一次才彻底执行这里的代码
synchronized (Singleton.class){
if(singleton==null){
singleton=new Singleton();
}
}
}
return singleton;
}
}
问:难道我不能创建一个类,把所有的方法和变量都定义为静态的,把类直接当做一个单件? 答:如果你的类自给自足,而且不依赖于负责的初始化,那么你可以这么做,但是,因为静态初始化的控制权实在Java手上,这么做有可能导致混乱,特别是当有许多类牵涉其中的时候,这么做常常会造成一些微妙的,不容易发现的和初始化的次序有关的Bug,除非你有绝对的必要使用类的单件,否则还是建议使用对象的单件,比较保险。
问:那么类加载器(classloader)呢?听说两个类加载器可能有机会各自创建自己的单件实例。 答:是的,每个类加载器都定义了一个命名空间,如果有两个以上的类加载器,不同的类加载器可能会加载同一个类,从整个程序来看,同一个类会被加载多次,如果这样的事情发生在单件上,就会产生多个单件并存在怪异现象,所以,如果你的程序有多个类加载器又同时使用了单件模式,请小心,有一个解决办法:自行制定类加载器, 并制定同一个类加载器。
问:我想把单件类当成超类,设计出子类,但是我遇到了问题:究竟可不可以继承单件类? 答:继承单件类会遇到一个问题,构造器是私有的,到时候就必须把构造器改成公开的或受保护的,但是这么一来就不算是“真正的”单件了,别的类可以实例化它。 如果你真把构造器的访问权限改了,还有另一个问题会出现,单件的实现是利用静态变量,直接继承会导致所有的派生类共享同一个实例变量,这可能不是你想要的,所以,想要让子类能工作顺利,基类必须事项注册表功能。 在这么做之前,你得想想,继承单件能带来什么好处,还有通常适合使用单件模式的机会不多。
问:我还是不了解为何全局变量比单件模式差。 答:在Java中,全局变量基本上就是对对象的静态引用,在这样的情况下使用全局变量会有一些缺点,我们已经提到了其中的一个:急切实例化VS.延迟实例化。但是我们要记住这个模式的目的:确保类只有一个实例并提供全局访问。全局变量可以提供全局访问,但是不能确保只有一个实例。全局变量也会变相鼓励开发人员,用许多全局变量指向许多小对象来造成命名空间的污染。 单件不鼓励这样的现象,但单件任然可能被滥用。
四、迭代器模式
参考网址1:http://www.runoob.com/design-pattern/iterator-pattern.html
介绍
意图:提供一种方法顺序访问一个聚合对象中各个元素, 而又无须暴露该对象的内部表示。
主要解决:不同的方式来遍历整个整合对象。
何时使用:遍历一个聚合对象。
如何解决:把在元素之间游走的责任交给迭代器,而不是聚合对象。
关键代码:定义接口:hasNext, next。
应用实例:JAVA 中的 iterator。
优点: 1、它支持以不同的方式遍历一个聚合对象。 2、迭代器简化了聚合类。 3、在同一个聚合上可以有多个遍历。 4、在迭代器模式中,增加新的聚合类和迭代器类都很方便,无须修改原有代码。
缺点:由于迭代器模式将存储数据和遍历数据的职责分离,增加新的聚合类需要对应增加新的迭代器类,类的个数成对增加,这在一定程度上增加了系统的复杂性。
使用场景: 1、访问一个聚合对象的内容而无须暴露它的内部表示。 2、需要为聚合对象提供多种遍历方式。 3、为遍历不同的聚合结构提供一个统一的接口。
注意事项:迭代器模式就是分离了集合对象的遍历行为,抽象出一个迭代器类来负责,这样既可以做到不暴露集合的内部结构,又可让外部代码透明地访问集合内部的数据。
实现
我们将创建一个叙述导航方法的 Iterator 接口和一个返回迭代器的 Container 接口。实现了 Container 接口的实体类将负责实现 Iterator 接口。
IteratorPatternDemo,我们的演示类使用实体类 NamesRepository 来打印 NamesRepository 中存储为集合的 Names。
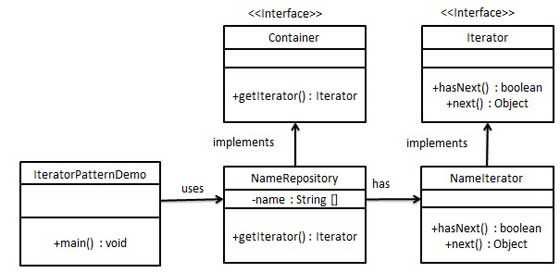
参考网址2:https://blog.csdn.net/zhengzhb/article/details/7610745
public static void print(Collection coll){
Iterator it = coll.iterator();
while(it.hasNext()){
String str = (String)it.next();
System.out.println(str);
}
}
这个方法的作用是循环打印一个字符串集合,里面就用到了迭代器模式,java语言已经完整地实现了迭代器模式,Iterator翻译成汉语就是迭代器的意思。提到迭代器,首先它是与集合相关的,集合也叫聚集、容器等,我们可以将集合看成是一个可以包容对象的容器,例如List,Set,Map,甚至数组都可以叫做集合,而迭代器的作用就是把容器中的对象一个一个地遍历出来。
迭代器模式的结构
- 抽象容器:一般是一个接口,提供一个iterator()方法,例如java中的Collection接口,List接口,Set接口等。
- 具体容器:就是抽象容器的具体实现类,比如List接口的有序列表实现ArrayList,List接口的链表实现LinkList,Set接口的哈希列表的实现HashSet等。
- 抽象迭代器:定义遍历元素所需要的方法,一般来说会有这么三个方法:取得第一个元素的方法first(),取得下一个元素的方法next(),判断是否遍历结束的方法isDone()(或者叫hasNext()),移出当前对象的方法remove(),
- 迭代器实现:实现迭代器接口中定义的方法,完成集合的迭代。
迭代器模式的适用场景
迭代器模式是与集合共生共死的,一般来说,我们只要实现一个集合,就需要同时提供这个集合的迭代器,就像java中的Collection,List、Set、Map等,这些集合都有自己的迭代器。假如我们要实现一个这样的新的容器,当然也需要引入迭代器模式,给我们的容器实现一个迭代器。
但是,由于容器与迭代器的关系太密切了,所以大多数语言在实现容器的时候都给提供了迭代器,并且这些语言提供的容器和迭代器在绝大多数情况下就可以满足我们的需要,所以现在需要我们自己去实践迭代器模式的场景还是比较少见的,我们只需要使用语言中已有的容器和迭代器就可以了。 --------------------- > 参考网址3:<https://blog.csdn.net/yanbober/article/details/45497881>
核心 概念: 提供一种方法来访问聚合对象,而不用暴露这个对象的内部表示,其别名为游标(Cursor)。迭代器模式是一种对象行为型模式。
迭代器模式结构重要核心模块:
迭代器角色(Iterator)
迭代器角色负责定义访问和遍历元素的接口。
具体迭代器角色(Concrete Iterator)
具体迭代器角色要实现迭代器接口,并要记录遍历中的当前位置。
容器角色(Container)
容器角色负责提供创建具体迭代器角色的接口。
具体容器角色(Concrete Container)
具体容器角色实现创建具体迭代器角色的接口——这个具体迭代器角色于该容器的结构相关。
迭代器模式中应用了工厂方法模式,抽象迭代器对应于抽象产品角色,具体迭代器对应于具体产品角色,抽象聚合类对应于抽象工厂角色,具体聚合类对应于具体工厂角色。
使用场景 访问一个聚合对象的内容而无需暴露它的内部表示。
支持对聚合对象的多种遍历。
为遍历不同的聚合结构提供一个统一的接口(即, 支持多态迭代)。
迭代器模式是与集合共生共死的,一般来说,我们只要实现一个集合,就需要同时提供这个集合的迭代器,就像java中的Collection,List、Set、Map等,这些集合都有自己的迭代器。假如我们要实现一个这样的新的容器,当然也需要引入迭代器模式,给我们的容器实现一个迭代器。但是,由于容器与迭代器的关系太密切了,所以大多数语言在实现容器的时候都给提供了迭代器,并且这些语言提供的容器和迭代器在绝大多数情况下就可以满足我们的需要,所以现在需要我们自己去实践迭代器模式的场景还是比较少见的,我们只需要使用语言中已有的容器和迭代器就可以了。
一、迭代器模式定义
迭代器模式提供一种方法顺序访问一个聚合对象中的各个元素,而又不暴露其内部的表示。把游走的任务放在迭代器上,而不是聚合上。这样简化了聚合的接口和实现,也让责任各得其所。
二、迭代器模式结构

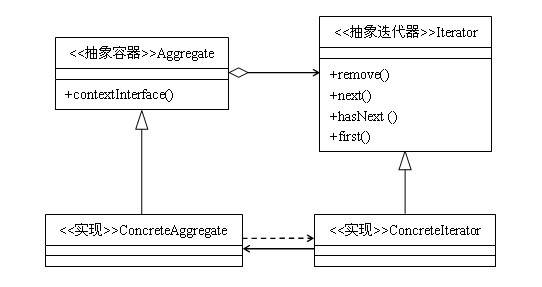
迭代器模式涉及到以下几个角色:
● 抽象迭代器(Iterator)角色:此抽象角色定义出遍历元素所需的接口。
● 具体迭代器(ConcreteIterator)角色:此角色实现了Iterator接口,并保持迭代过程中的游标位置。
● 聚集(Aggregate)角色:此抽象角色给出创建迭代器(Iterator)对象的接口。
● 具体聚集(ConcreteAggregate)角色:实现了创建迭代器(Iterator)对象的接口,返回一个合适的具体迭代器实例。
● 客户端(Client)角色:持有对聚集及其迭代器对象的引用,调用迭代子对象的迭代接口,也有可能通过迭代子操作聚集元素的增加和删除。
抽象聚集角色类,这个角色规定出所有的具体聚集必须实现的接口。迭代器模式要求聚集对象必须有一个工厂方法,也就是createIterator()方法,以向外界提供迭代器对象的实例。
public abstract class Aggregate {
/**
* 工厂方法,创建相应迭代子对象的接口
*/
public abstract Iterator createIterator();
}
具体聚集角色类,实现了抽象聚集角色类所要求的接口,也就是createIterator()方法。此外,还有方法getElement()向外界提供聚集元素,而方法size()向外界提供聚集的大小等。
public class ConcreteAggregate extends Aggregate {
private Object[] objArray = null;
/**
* 构造方法,传入聚合对象的具体内容
*/
public ConcreteAggregate(Object[] objArray){
this.objArray = objArray;
}
@Override
public Iterator createIterator() {
return new ConcreteIterator(this);
}
/**
* 取值方法:向外界提供聚集元素
*/
public Object getElement(int index){
if(index < objArray.length){
return objArray[index];
}else{
return null;
}
}
/**
* 取值方法:向外界提供聚集的大小
*/
public int size(){
return objArray.length;
}
}
抽象迭代器角色类
public interface Iterator {
/**
* 迭代方法:移动到第一个元素
*/
public void first();
/**
* 迭代方法:移动到下一个元素
*/
public void next();
/**
* 迭代方法:是否为最后一个元素
*/
public boolean isDone();
/**
* 迭代方法:返还当前元素
*/
public Object currentItem();
}
具体迭代器角色类
public class ConcreteIterator implements Iterator {
//持有被迭代的具体的聚合对象
private ConcreteAggregate agg;
//内部索引,记录当前迭代到的索引位置
private int index = 0;
//记录当前聚集对象的大小
private int size = 0;
public ConcreteIterator(ConcreteAggregate agg){
this.agg = agg;
this.size = agg.size();
index = 0;
}
/**
* 迭代方法:返还当前元素
*/
@Override
public Object currentItem() {
return agg.getElement(index);
}
/**
* 迭代方法:移动到第一个元素
*/
@Override
public void first() {
index = 0;
}
/**
* 迭代方法:是否为最后一个元素
*/
@Override
public boolean isDone() {
return (index >= size);
}
/**
* 迭代方法:移动到下一个元素
*/
@Override
public void next() {
if(index < size)
{
index ++;
}
}
}
客户端类
public class Client {
public void operation(){
Object[] objArray = {"One","Two","Three","Four","Five","Six"};
//创建聚合对象
Aggregate agg = new ConcreteAggregate(objArray);
//循环输出聚合对象中的值
Iterator it = agg.createIterator();
while(!it.isDone()){
System.out.println(it.currentItem());
it.next();
}
}
public static void main(String[] args) {
Client client = new Client();
client.operation();
}
}
三、迭代器模式的应用
如果要问Java中使用最多的一种模式,答案不是单例模式,也不是工厂模式,更不是策略模式,而是迭代器模式,先来看一段代码吧:
public static void print(Collection coll){
Iterator it = coll.iterator();
while(it.hasNext()){
String str = (String)it.next();
System.out.println(str);
}
}
这个方法的作用是循环打印一个字符串集合,里面就用到了迭代器模式,java语言已经完整地实现了迭代器模式,例如List,Set,Map,而迭代器的作用就是把容器中的对象一个一个地遍历出来。
四、迭代器模式的优缺点
优点
①简化了遍历方式,对于对象集合的遍历,还是比较麻烦的,对于数组或者有序列表,我们尚可以通过游标来取得,但用户需要在对集合了解很清楚的前提下,自行遍历对象,但是对于hash表来说,用户遍历起来就比较麻烦了。而引入了迭代器方法后,用户用起来就简单的多了。
②可以提供多种遍历方式,比如说对有序列表,我们可以根据需要提供正序遍历,倒序遍历两种迭代器,用户用起来只需要得到我们实现好的迭代器,就可以方便的对集合进行遍历了。
③封装性良好,用户只需要得到迭代器就可以遍历,而对于遍历算法则不用去关心。
缺点
对于比较简单的遍历(像数组或者有序列表),使用迭代器方式遍历较为繁琐,大家可能都有感觉,像ArrayList,我们宁可愿意使用for循环和get方法来遍历集合。
五、迭代器的应用场景
迭代器模式是与集合共生共死的,一般来说,我们只要实现一个集合,就需要同时提供这个集合的迭代器,就像java中的Collection,List、Set、Map等,这些集合都有自己的迭代器。假如我们要实现一个这样的新的容器,当然也需要引入迭代器模式,给我们的容器实现一个迭代器。
但是,由于容器与迭代器的关系太密切了,所以大多数语言在实现容器的时候都给提供了迭代器,并且这些语言提供的容器和迭代器在绝大多数情况下就可以满足我们的需要,所以现在需要我们自己去实践迭代器模式的场景还是比较少见的,我们只需要使用语言中已有的容器和迭代器就可以了。




