
一、开闭原则
参考网址1:https://blog.csdn.net/zhengzhb/article/details/7296944
定义:一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。
问题由来:在软件的生命周期内,因为变化、升级和维护等原因需要对软件原有代码进行修改时,可能会给旧代码中引入错误,也可能会使我们不得不对整个功能进行重构,并且需要原有代码经过重新测试。
解决方案:当软件需要变化时,尽量通过扩展软件实体的行为来实现变化,而不是通过修改已有的代码来实现变化。
参考网址2:https://blog.csdn.net/LoveLion/article/details/7537584
在开闭原则的定义中,软件实体可以指一个软件模块、一个由多个类组成的局部结构或一个独立的类。
任何软件都需要面临一个很重要的问题,即它们的需求会随时间的推移而发生变化。当软件系统需要面对新的需求时,我们应该尽量保证系统的设计框架是稳定的。如果一个软件设计符合开闭原则,那么可以非常方便地对系统进行扩展,而且在扩展时无须修改现有代码,使得软件系统在拥有适应性和灵活性的同时具备较好的稳定性和延续性。随着软件规模越来越大,软件寿命越来越长,软件维护成本越来越高,设计满足开闭原则的软件系统也变得越来越重要。
为了满足开闭原则,需要对系统进行抽象化设计,抽象化是开闭原则的关键。在Java、C#等编程语言中,可以为系统定义一个相对稳定的抽象层,而将不同的实现行为移至具体的实现层中完成。在很多面向对象编程语言中都提供了接口、抽象类等机制,可以通过它们定义系统的抽象层,再通过具体类来进行扩展。如果需要修改系统的行为,无须对抽象层进行任何改动,只需要增加新的具体类来实现新的业务功能即可,实现在不修改已有代码的基础上扩展系统的功能,达到开闭原则的要求。
Sunny软件公司开发的CRM系统可以显示各种类型的图表,如饼状图和柱状图等,为了支持多种图表显示方式,原始设计方案如图1所示: 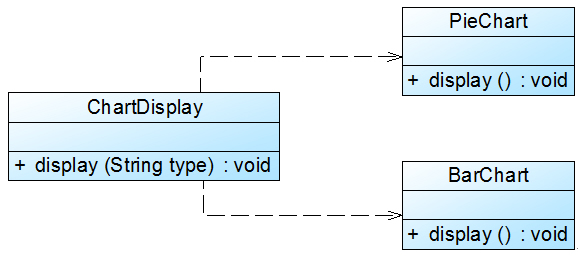 图1 初始设计方案结构图 在ChartDisplay类的display()方法中存在如下代码片段:
图1 初始设计方案结构图 在ChartDisplay类的display()方法中存在如下代码片段: ......if (type.equals("pie")) { PieChart chart = new PieChart(); chart.display();}else if (type.equals("bar")) { BarChart chart = new BarChart(); chart.display();}...... 在该代码中,如果需要增加一个新的图表类,如折线图LineChart,则需要修改ChartDisplay类的display()方法的源代码,增加新的判断逻辑,违反了开闭原则。 现对该系统进行重构,使之符合开闭原则。
在本实例中,由于在ChartDisplay类的display()方法中针对每一个图表类编程,因此增加新的图表类不得不修改源代码。可以通过抽象化的方式对系统进行重构,使之增加新的图表类时无须修改源代码,满足开闭原则。具体做法如下:
(1) 增加一个抽象图表类AbstractChart,将各种具体图表类作为其子类;
(2) ChartDisplay类针对抽象图表类进行编程,由客户端来决定使用哪种具体图表。
重构后结构如图2所示:
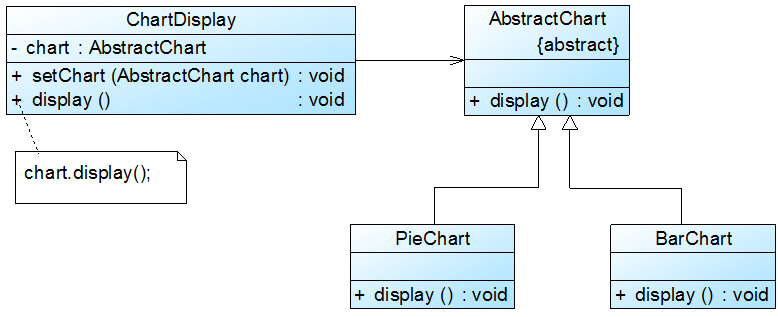
图2 重构后的结构图
在图2中,我们引入了抽象图表类AbstractChart,且ChartDisplay针对抽象图表类进行编程,并通过setChart()方法由客户端来设置实例化的具体图表对象,在ChartDisplay的display()方法中调用chart对象的display()方法显示图表。如果需要增加一种新的图表,如折线图LineChart,只需要将LineChart也作为AbstractChart的子类,在客户端向ChartDisplay中注入一个LineChart对象即可,无须修改现有类库的源代码。
注意:因为xml和properties等格式的配置文件是纯文本文件,可以直接通过VI编辑器或记事本进行编辑,且无须编译,因此在软件开发中,一般不把对配置文件的修改认为是对系统源代码的修改。如果一个系统在扩展时只涉及到修改配置文件,而原有的Java代码或C#代码没有做任何修改,该系统即可认为是一个符合开闭原则的系统。
参考网址3:https://blog.csdn.net/hfreeman2008/article/details/52344022
我们举例说明什么是开闭原则,以书店销售书籍为例,其类图如下:
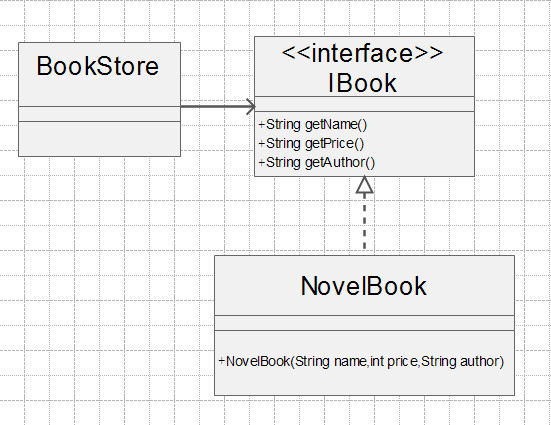
书籍接口:
public interface IBook{
public String getName();
public String getPrice();
public String getAuthor();
}12345
小说类书籍:
public class NovelBook implements IBook{
private String name;
private int price;
private String author;
public NovelBook(String name,int price,String author){
this.name = name;
this.price = price;
this.author = author;
}
public String getAutor(){
return this.author;
}
public String getName(){
return this.name;
}
public int getPrice(){
return this.price;
}
}1234567891011121314151617181920212223
Client类:
public class Client{
public static void main(Strings[] args){
IBook novel = new NovelBook("笑傲江湖",100,"金庸");
System.out.println("书籍名字:"+novel.getName()+"书籍作者:"+novel.getAuthor()+"书籍价格:"+novel.getPrice());
}
}1234567
项目投产生,书籍正常销售,但是我们经常因为各种原因,要打折来销售书籍,这是一个变化,我们要如何应对这样一个需求变化呢?
我们有下面三种方法可以解决此问题:
-
修改接口 在IBook接口中,增加一个方法getOffPrice(),专门用于进行打折处理,所有的实现类实现此方法。但是这样的一个修改方式,实现类NovelBook要修改,同时IBook接口应该是稳定且可靠,不应该经常发生改变,否则接口作为契约的作用就失去了。因此,此方案否定。
-
修改实现类 修改NovelBook类的方法,直接在getPrice()方法中实现打折处理。此方法是有问题的,例如我们如果getPrice()方法中只需要读取书籍的打折前的价格呢?这不是有问题吗?当然我们也可以再增加getOffPrice()方法,这也是可以实现其需求,但是这就有二个读取价格的方法,因此,该方案也不是一个最优方案。
-
通过扩展实现变化 我们可以增加一个子类OffNovelBook,覆写getPrice方法。此方法修改少,对现有的代码没有影响,风险少,是个好办法。
下面是修改后的类图:
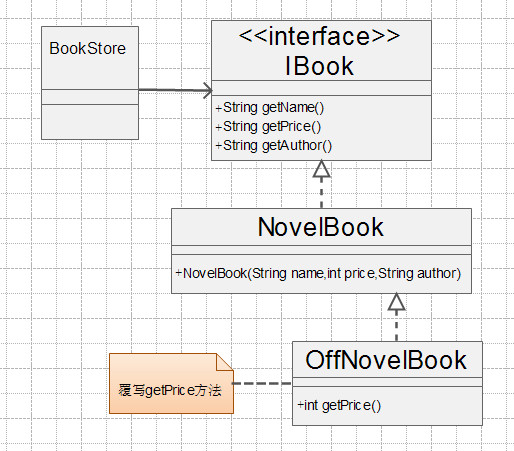
打折类:
public class OffNovelBook implements NovelBook{
public OffNovelBook(String name,int price,String author){
super(name,price,author);
}
//覆写价格方法,当价格大于40,就打8析,其他价格就打9析
public int getPrice(){
if(this.price > 40){
return this.price * 0.8;
}else{
return this.price * 0.9;
}
}
}123456789101112131415
现在打折销售开发完成了,我们只是增加了一个OffNovelBook类,我们修改的代码都是高层次的模块,没有修改底层模块,代码改变量少,可以有效的防止风险的扩散。
我们可以把变化归纳为二种类型:
- 逻辑变化 只变化了一个逻辑,而不涉及其他模块,比如一个算法是abc,现在需要修改为a+b+c,可以直接通过修改原有类中的方法的方式来完成,前提条件是所有依赖或关联类都按照相同的逻辑处理
- 子模块变化 一人模块变化,会对其它的模块产生影响,特别是一个低层次的模块变化必然引起高层模块的变化,因此在通过扩展完成变化。
为什么使用开闭原则
第一:开闭原则非常有名,只要是面向对象编程,在开发时都会强调开闭原则
第二:开闭原则是最基础的设计原则,其它的五个设计原则都是开闭原则的具体形态,也就是说其它的五个设计原则是指导设计的工具和方法,而开闭原则才是其精神领袖。依照java语言的称谓,开闭原则是抽象类,而其它的五个原则是具体的实现类。
第三:开闭原则可以提高复用性 在面向对象的设计中,所有的逻辑都是从原子逻辑组合而来,不是在一个类中独立实现一个业务逻辑。只有这样的代码才可以复用,粒度越小,被复用的可能性越大。那为什么要复用呢?减少代码的重复,避免相同的逻辑分散在多个角落,减少维护人员的工作量。那怎么才能提高复用率呢?缩小逻辑粒度,直到一个逻辑不可以分为止。
第四:开闭原则可以提高维护性 一款软件量产后,维护人员的工作不仅仅对数据进行维护,还可能要对程序进行扩展,维护人员最乐意的事是扩展一个类,而不是修改一个类。让维护人员读懂原有代码,再进行修改,是一件非常痛苦的事情,不要让他在原有的代码海洋中游荡后再修改,那是对维护人员的折磨和摧残。
第五:面向对象开发的要求 万物皆对象,我们要把所有的事物抽象成对象,然后针对对象进行操作,但是万物皆发展变化,有变化就要有策略去应对,怎么快速应对呢?这就需要在设计之初考虑到所有可能变化的因素,然后留下接口,等待“可能”转变为“现实”。
如何使用开闭原则
第一:抽象约束 抽象是对一组事物的通用描述,没有具体的实现,也就表示它可以有非常多的可能性,可以跟随需求的变化而变化。因此,通过接口或抽象类可以约束一组可能变化的行为,并且能够实现对扩展开放,其包含三层含义:
- 通过接口或抽象类约束扩散,对扩展进行边界限定,不允许出现在接口或抽象类中不存在的public方法。
- 参数类型,引用对象尽量使用接口或抽象类,而不是实现类,这主要是实现里氏替换原则的一个要求
- 抽象层尽量保持稳定,一旦确定就不要修改
第二:元数据(metadata)控件模块行为 编程是一个很苦很累的活,那怎么才能减轻压力呢?答案是尽量使用元数据来控制程序的行为,减少重复开发。什么是元数据?用来描述环境和数据的数据,通俗的说就是配置参数,参数可以从文件中获得,也可以从数据库中获得。
第三:制定项目章程 在一个团队中,建立项目章程是非常重要的,因为章程是所有人员都必须遵守的约定,对项目来说,约定优于配置。这比通过接口或抽象类进行约束效率更高,而扩展性一点也没有减少。
第四:封装变化 对变化封装包含两层含义: (1)将相同的变化封装到一个接口或抽象类中 (2)将不同的变化封装到不同的接口或抽象类中,不应该有两个不同的变化出现在同一个接口或抽象类中。 封装变化,也就是受保护的变化,找出预计有变化或不稳定的点,我们为这些变化点创建稳定的接口。
参考网址4:https://wizardforcel.gitbooks.io/design-pattern-lessons/content/lesson7.html
实例
在软件开发过程中,永远不变的就是变化。开闭原则是使我们的软件系统拥抱变化的核心原则之一。对扩展可放,对修改关闭给出了高层次的概括,即在需要对软件进行升级、变化时应该通过扩展的形式来实现,而非修改原有代码。当然这只是一种比较理想的状态,是通过扩展还是通过修改旧代码需要根据代码自身来定。
在Volley中,开闭原则体现得比较好的是Request类族的设计。我们知道,在开发C/S应用时,服务器返回的数据格式多种多样,有字符串类型、xml、json等。而解析服务器返回的Response的原始数据类型则是通过Request类来实现的,这样就使得Request类对于服务器返回的数据格式有良好的扩展性,即Request的可变性太大。
例如我们返回的数据格式是Json,那么我们使用JsonObjectRequest请求来获取数据,它会将结果转成JsonObject对象,我们看看JsonObjectRequest的核心实现。
/**
* A request for retrieving a {@link JSONObject} response body at a given URL, allowing for an
* optional {@link JSONObject} to be passed in as part of the request body.
*/
public class JsonObjectRequest extends JsonRequest<JSONObject> {
// 代码省略
@Override
protected Response<JSONObject> parseNetworkResponse(NetworkResponse response) {
try {
String jsonString =
new String(response.data, HttpHeaderParser.parseCharset(response.headers));
return Response.success(new JSONObject(jsonString),
HttpHeaderParser.parseCacheHeaders(response));
} catch (UnsupportedEncodingException e) {
return Response.error(new ParseError(e));
} catch (JSONException je) {
return Response.error(new ParseError(je));
}
}
}
JsonObjectRequest通过实现Request抽象类的parseNetworkResponse解析服务器返回的结果,这里将结果转换为JSONObject,并且封装到Response类中。
例如Volley添加对图片请求的支持,即ImageLoader( 已内置 )。这个时候我的请求返回的数据是Bitmap图片。因此我需要在该类型的Request得到的结果是Request,但支持一种数据格式不能通过修改源码的形式,这样可能会为旧代码引入错误。但是你又需要支持新的数据格式,此时我们的开闭原则就很重要了,对扩展开放,对修改关闭。我们看看Volley是如何做的。
/**
* A canned request for getting an image at a given URL and calling
* back with a decoded Bitmap.
*/
public class ImageRequest extends Request<Bitmap> {
// 代码省略
// 将结果解析成Bitmap,并且封装套Response对象中
@Override
protected Response<Bitmap> parseNetworkResponse(NetworkResponse response) {
// Serialize all decode on a global lock to reduce concurrent heap usage.
synchronized (sDecodeLock) {
try {
return doParse(response);
} catch (OutOfMemoryError e) {
VolleyLog.e("Caught OOM for %d byte image, url=%s", response.data.length, getUrl());
return Response.error(new ParseError(e));
}
}
}
/**
* The real guts of parseNetworkResponse. Broken out for readability.
*/
private Response<Bitmap> doParse(NetworkResponse response) {
byte[] data = response.data;
BitmapFactory.Options decodeOptions = new BitmapFactory.Options();
Bitmap bitmap = null;
// 解析Bitmap的相关代码,在此省略
if (bitmap == null) {
return Response.error(new ParseError(response));
} else {
return Response.success(bitmap, HttpHeaderParser.parseCacheHeaders(response));
}
}
}
需要添加某种数据格式的Request时,只需要继承自Request类,并且实现相应的方法即可。这样通过扩展的形式来应对软件的变化或者说用户需求的多样性,即避免了破坏原有系统,又保证了软件系统的可扩展性。
参考网址5(很详细):http://blog.jobbole.com/99617/
二、依赖倒置原则
参考网址1:https://www.cnblogs.com/hellojava/archive/2013/03/19/2966684.html
现在我们来通过实例还原开篇问题的场景,以便更好的来理解。下面代码描述了一个简单的场景,Jim作为人有吃的方法,苹果有取得自己名字的方法,然后实现Jim去吃苹果。
代码如下:
//具体Jim人类
public class Jim {
public void eat(Apple apple){
System.out.println("Jim eat " + apple.getName());
}
}
//具体苹果类
public class Apple {
public String getName(){
return "apple";
}
}
public class Client {
public static void main(String[] args) {
Jim jim = new Jim();
Apple apple = new Apple();
jim.eat(apple);
}
}
运行结果:Jim eat apple
上面代码看起来比较简单,但其实是一个非常脆弱的设计。现在Jim可以吃苹果了,但是不能只吃苹果而不吃别的水果啊,这样下去肯定会造成营养失衡。现在想让Jim吃香蕉了(好像香蕉里含钾元素比较多,吃点比较有益),突然发现Jim是吃不了香蕉的,那怎么办呢?看来只有修改代码了啊,由于上面代码中Jim类依赖于Apple类,所以导致不得不去改动Jim类里面的代码。那如果下次Jim又要吃别的水果了呢?继续修改代码?这种处理方式显然是不可取的,频繁修改会带来很大的系统风险,改着改着可能就发现Jim不会吃水果了。
上面的代码之所以会出现上述难堪的问题,就是因为Jim类依赖于Apple类,两者是紧耦合的关系,其导致的结果就是系统的可维护性大大降低。要增加香蕉类却要去修改Jim类代码,这是不可忍受的,你改你的代码为什么要动我的啊,显然Jim不乐意了。我们常说要设计一个健壮稳定的系统,而这里只是增加了一个香蕉类,就要去修改Jim类,健壮和稳定还从何谈起。
而根据依赖倒置原则,我们可以对上述代码做些修改,提取抽象的部分。首先我们提取出两个接口:People和Fruit,都提供各自必需的抽象方法,这样以后无论是增加Jim人类,还是增加Apple、Banana等各种水果,都只需要增加自己的实现类就可以了。由于遵循依赖倒置原则,只依赖于抽象,而不依赖于细节,所以增加类无需修改其他类。
代码如下:
//人接口
public interface People {
public void eat(Fruit fruit);//人都有吃的方法,不然都饿死了
}
//水果接口
public interface Fruit {
public String getName();//水果都是有名字的
}
//具体Jim人类
public class Jim implements People{
public void eat(Fruit fruit){
System.out.println("Jim eat " + fruit.getName());
}
}
//具体苹果类
public class Apple implements Fruit{
public String getName(){
return "apple";
}
}
//具体香蕉类
public class Banana implements Fruit{
public String getName(){
return "banana";
}
}
public class Client {
public static void main(String[] args) {
People jim = new Jim();
Fruit apple = new Apple();
Fruit Banana = new Banana();//这里符合了里氏替换原则
jim.eat(apple);
jim.eat(Banana);
}
}
运行结果:
Jim eat apple Jim eat banana
- People类是复杂的业务逻辑,属于高层模块,而Fruit是原子模块,属于低层模块。People依赖于抽象的Fruit接口,这就做到了:高层模块不应该依赖低层模块,两者都应该依赖于抽象(抽象类或接口)。
- People和Fruit接口与各自的实现类没有关系,增加实现类不会影响接口,这就做到了:抽象(抽象类或接口)不应该依赖于细节(具体实现类)。
- Jim、Apple、Banana实现类都要去实现各自的接口所定义的抽象方法,所以是依赖于接口的。这就做到了:细节(具体实现类)应该依赖抽象。
下面我们来看一个具体的例子。
class Video {
public void run() {
System.out.println("正常播放MP4视频");
}
}
class VideoPlayer {
public void play(Video video) {
video.run();
}
}
public class VideoTest {
public static void main(String[] args) {
VideoPlayer player = new VideoPlayer();
Video video = new Video();
player.play(video);
}
}
这里我们做了一个简单的视频播放软件,播放一段MP4的视频。
运行结果 :
<pre name="code" class="java">正常播放MP4视频
一段时间过后,来了一段AVI格式的视频,这个时候我们的视频播放器就没有办法了,于是我们必须修改代码,修改代码如下
class VideoMP4 {
public void run() {
System.out.println("正常播放MP4视频");
}
}
class VideoAVI {
public void run() {
System.out.println("正常播放AVI视频");
}
}
class VideoPlayer {
public void play(VideoMP4 video) {
video.run();
}
public void play(VideoAVI video) {
video.run();
}
}
public class VideoTest {
public static void main(String[] args) {
VideoPlayer player = new VideoPlayer();
VideoAVI video = new VideoAVI();
player.play(video);
}
}
废了九牛二虎之力,修改了所有Java类,终于AVI格式的视频也能播放了。好了,以后每当新加一种视频格式,我们就要不断的修改VideoPlayer。这显然不是我们所希望的。出现这个问题的原因就是VideoPlayer和Video高度耦合,我们必须降低他们直接的耦合。这里我们引入一个IVideo的接口
public interface IVideo{
public void run();
}
VideoPlayer和Video不再依赖于细节,而依赖于IVideo接口,这就符合我们上面所说的依赖倒置原则。修改之后的代码如下
class VideoMP4 implements IVideo{
public void run() {
System.out.println("正常播放MP4视频");
}
}
class VideoAVI implements IVideo{
public void run() {
System.out.println("正常播放AVI视频");
}
}
class VideoWMV implements IVideo{
public void run(){
System.out.prinitl("正常播放WMV视频");
}
}
class VideoPlayer {
public void play(IVideo video) {
video.run();
}
}
public class VideoTest {
public static void main(String[] args) {
VideoPlayer player = new VideoPlayer();
IVideo video = new VideoAVI();
player.play(video);
}
}
通过这样修改之后,以后你无论新添多少中视频格式,VideoPlayer都无需修改一行代码。在实际开发中也是,一旦我们的播放器开发完成,如果反复对其进行修改的话,产生的风险是非常大,极易出现问题。这里ViderPlayer是调用端,也就是依赖倒置中的高层模块,与之相应的Video就是底层模块。这就是高层模块不应该依赖低层模块,二者都应该依赖其抽象;抽象不应该依赖细节;细节应该依赖抽象。
总之一句话依赖倒置的核心思想:面向接口编程!理解了面向接口编程也就理解了依赖倒置原则!
参考网址3(代码较长,较详细):https://zhuanlan.zhihu.com/p/24175489
1、官方定义
依赖倒置原则,英文缩写DIP,全称Dependence Inversion Principle。
原始定义:High level modules should not depend upon low level modules. Both should depend upon abstractions. Abstractions should not depend upon details. Details should depend upon abstractions。
官方翻译:高层模块不应该依赖低层模块,两者都应该依赖其抽象;抽象不应该依赖细节,细节应该依赖抽象。
2、自己理解
2.1、原理解释
上面的定义不难理解,主要包含两次意思:
1)高层模块不应该直接依赖于底层模块的具体实现,而应该依赖于底层的抽象。换言之,模块间的依赖是通过抽象发生,实现类之间不发生直接的依赖关系,其依赖关系是通过接口或抽象类产生的。
2)接口和抽象类不应该依赖于实现类,而实现类依赖接口或抽象类。这一点其实不用多说,很好理解,“面向接口编程”思想正是这点的最好体现。
2.2、被“倒置”的依赖
相比传统的软件设计架构,比如我们常说的经典的三层架构,UI层依赖于BLL层,BLL层依赖于DAL层。由于每一层都是依赖于下层的实现,这样当某一层的结构发生变化时,它的上层就不得不也要发生改变,比如我们DAL里面逻辑发生了变化,可能会导致BLL和UI层都随之发生变化,这种架构是非常荒谬的!好,这个时候如果我们换一种设计思路,高层模块不直接依赖低层的实现,而是依赖于低层模块的抽象,具体表现为我们增加一个IBLL层,里面定义业务逻辑的接口,UI层依赖于IBLL层,BLL层实现IBLL里面的接口,所以具体的业务逻辑则定义在BLL里面,这个时候如果我们BLL里面的逻辑发生变化,只要接口的行为不变,上层UI里面就不用发生任何变化。
在经典的三层里面,高层模块直接依赖低层模块的实现,当我们将高层模块依赖于底层模块的抽象时,就好像依赖“倒置”了。这就是依赖倒置的由来。通过依赖倒置,可以使得架构更加稳定、更加灵活、更好应对需求变化。
2.3、依赖倒置的目的
上面说了,在三层架构里面增加一个接口层能实现依赖倒置,它的目的就是降低层与层之间的耦合,使得设计更加灵活。从这点上来说,依赖倒置原则也是“松耦合”设计的很好体现。
二、场景示例
文章最开始的时候说了,依赖倒置是设计模式的设计原则之一,那么在我们那么多的设计模式中,哪些设计模式遵循了依赖倒置的原则呢?这个就多了,比如我们常见的工厂方法模式。下面博主就结合一个使用场景来说说依赖倒置原则如何能够使得设计更加灵活。
场景描述:还记得在一场风花雪月的邂逅:接口和抽象类这篇里面介绍过设备的采集的例子,这篇继续以这个使用场景来说明。设备有很多类型,每种设备都有登录和采集两个方法,通过DeviceService这个服务去启动设备的采集,最开始我们只有MML和TL2这两种类型的设备,那么来看看我们的设计代码。
代码示例:
//MML类型的设备
public class DeviceMML
{
public void Login()
{
Console.WriteLine("MML设备登录");
}
public bool Spider()
{
Console.WriteLine("MML设备采集");
return true;
}
}
//TL2类型设备
public class DeviceTL2
{
public void Login()
{
Console.WriteLine("TL2设备登录");
}
public bool Spider()
{
Console.WriteLine("TL2设备采集");
return true;
}
}
//设备采集的服务
public class DeviceService
{
private DeviceMML MML = null;
private DeviceTL2 TL2 = null;
private string m_type = null;
//构造函数里面通过类型来判断是哪种类型的设备
public DeviceService(string type)
{
m_type = type;
if (type == "0")
{
MML = new DeviceMML();
}
else if (type == "1")
{
TL2 = new DeviceTL2();
}
}
public void LoginDevice()
{
if (m_type == "0")
{
MML.Login();
}
else if (m_type == "1")
{
TL2.Login();
}
}
public bool DeviceSpider()
{
if (m_type == "0")
{
return MML.Spider();
}
else if (m_type == "1")
{
return TL2.Spider();
}
else
{
return true;
}
}
}
在Main函数里面调用
class Program
{
static void Main(string[] args)
{
var oSpider = new DeviceService("1");
oSpider.LoginDevice();
var bRes = oSpider.DeviceSpider();
Console.ReadKey();
}
上述代码经过开发、调试、部署、上线。可以正常运行,貌似一切都OK。
日复一日、年复一年。后来公司又来两种新的设备TELNET和TL5类型设备。于是程序猿们又有得忙了,加班,赶进度!于是代码变成了这样:
//MML类型的设备
public class DeviceMML
{
public void Login()
{
Console.WriteLine("MML设备登录");
}
public bool Spider()
{
Console.WriteLine("MML设备采集");
return true;
}
}
//TL2类型设备
public class DeviceTL2
{
public void Login()
{
Console.WriteLine("TL2设备登录");
}
public bool Spider()
{
Console.WriteLine("TL2设备采集");
return true;
}
}
//TELNET类型设备
public class DeviceTELNET
{
public void Login()
{
Console.WriteLine("TELNET设备登录");
}
public bool Spider()
{
Console.WriteLine("TELNET设备采集");
return true;
}
}
//TL5类型设备
public class DeviceTL5
{
public void Login()
{
Console.WriteLine("TL5设备登录");
}
public bool Spider()
{
Console.WriteLine("TL5设备采集");
return true;
}
}
//设备采集的服务
public class DeviceService
{
private DeviceMML MML = null;
private DeviceTL2 TL2 = null;
private DeviceTELNET TELNET = null;
private DeviceTL5 TL5 = null;
private string m_type = null;
//构造函数里面通过类型来判断是哪种类型的设备
public DeviceService(string type)
{
m_type = type;
if (type == "0")
{
MML = new DeviceMML();
}
else if (type == "1")
{
TL2 = new DeviceTL2();
}
else if (type == "2")
{
TELNET = new DeviceTELNET();
}
else if (type == "3")
{
TL5 = new DeviceTL5();
}
}
public void LoginDevice()
{
if (m_type == "0")
{
MML.Login();
}
else if (m_type == "1")
{
TL2.Login();
}
else if (m_type == "2")
{
TELNET.Login();
}
else if (m_type == "3")
{
TL5.Login();
}
}
public bool DeviceSpider()
{
if (m_type == "0")
{
return MML.Spider();
}
else if (m_type == "1")
{
return TL2.Spider();
}
else if (m_type == "2")
{
return TELNET.Spider();
}
else if (m_type == "3")
{
return TL5.Spider();
}
else
{
return true;
}
}
}
比如我们想启动TL5类型设备的采集,这样调用可以实现:
static void Main(string[] args)
{
var oSpider = new DeviceService("3");
oSpider.LoginDevice();
var bRes = oSpider.DeviceSpider();
Console.ReadKey();
}
花了九年二虎之力,总算是可以实现了。可是又过了段时间,又有新的设备类型呢?是不是又要加班,又要改。这样下去,感觉这就是一个无底洞,再加上时间越久,项目所经历的开发人员越容易发生变化,这个时候再改,那维护的成本堪比开发一个新的项目。并且,随着设备类型的增多,代码里面充斥着大量的if…else,这样的烂代码简直让人无法直视。
基于这种情况,如果我们当初设计这个系统的时候考虑了依赖倒置,那么效果可能截然不同。我们来看看依赖倒置如何解决以上问题的呢?
//定义一个统一接口用于依赖
public interface IDevice
{
void Login();
bool Spider();
}
//MML类型的设备
public class DeviceMML : IDevice
{
public void Login()
{
Console.WriteLine("MML设备登录");
}
public bool Spider()
{
Console.WriteLine("MML设备采集");
return true;
}
}
//TL2类型设备
public class DeviceTL2 : IDevice
{
public void Login()
{
Console.WriteLine("TL2设备登录");
}
public bool Spider()
{
Console.WriteLine("TL2设备采集");
return true;
}
}
//TELNET类型设备
public class DeviceTELNET : IDevice
{
public void Login()
{
Console.WriteLine("TELNET设备登录");
}
public bool Spider()
{
Console.WriteLine("TELNET设备采集");
return true;
}
}
//TL5类型设备
public class DeviceTL5 : IDevice
{
public void Login()
{
Console.WriteLine("TL5设备登录");
}
public bool Spider()
{
Console.WriteLine("TL5设备采集");
return true;
}
}
//设备采集的服务
public class DeviceService
{
private IDevice m_device;
public DeviceService(IDevice oDevice)
{
m_device = oDevice;
}
public void LoginDevice()
{
m_device.Login();
}
public bool DeviceSpider()
{
return m_device.Spider();
}
}
调用
static void Main(string[] args)
{
var oSpider = new DeviceService(new DeviceTL5());
oSpider.Login();
var bRes = oSpider.Spider();
Console.ReadKey();
}
代码说明:上述解决方案中,我们定义了一个IDevice接口,用于上层服务的依赖,也就是说,上层服务(这里指DeviceService)仅仅依赖IDevice接口,对于具体的实现类我们是不管的,只要接口的行为不发生变化,增加新的设备类型后,上层服务不用做任何的修改。这样设计降低了层与层之间的耦合,能很好地适应需求的变化,大大提高了代码的可维护性。呵呵,看着是不是有点眼熟?是不是有点像某个设计模式?其实设计模式的设计原理正是基于此。
参考网址4:https://www.jianshu.com/p/328a73e57e25
参考网址5:https://www.kancloud.cn/digest/xing-designpattern/143721




