
一、降低访问耦合
迪米特法则
定义:一个对象应该对其他对象保持最少的了解。
问题由来:类与类之间的关系越密切,耦合度越大,当一个类发生改变时,对另一个类的影响也越大。
解决方案:尽量降低类与类之间的耦合。
1. 迪米特法则又叫最少知道原则,通俗的来讲,就是一个类对自己依赖的类知道的越少越好。
2. 对于被依赖的类来说,无论逻辑多么复杂,都尽量地的将逻辑封装在类的内部,对外除了提供的public方法,不对外泄漏任何信息。
3. 迪米特法则还有一个更简单的定义:只与直接的朋友通信。
4. 直接的朋友:每个对象都会与其他对象有耦合关系,只要两个对象之间有耦合关系,我们就说这两个对象之间是朋友关系。
5. 耦合的方式很多,依赖、关联、组合、聚合等。其中,我们称出现成员变量、方法参数、方法返回值中的类为
直接的朋友,而出现在局部变量中的类则不是直接的朋友。也就是说,陌生的类最好不要作为局部变量的形式出现在类的内部。
例子1:
有一个集团公司,下属单位有分公司和直属部门,现在要求打印出所有下属单位的员工ID。先来看一下违反迪米特法则的设计。
//总公司员工
class Employee{
private String id;
public void setId(String id){
this.id = id;
}
public String getId(){
return id;
}
}
//分公司员工
class SubEmployee{
private String id;
public void setId(String id){
this.id = id;
}
public String getId(){
return id;
}
}
class SubCompanyManager{
public List<SubEmployee> getAllEmployee(){
List<SubEmployee> list = new ArrayList<SubEmployee>();
for(int i=0; i<100; i++){
SubEmployee emp = new SubEmployee();
//为分公司人员按顺序分配一个ID
emp.setId("分公司"+i);
list.add(emp);
}
return list;
}
}
class CompanyManager{
public List<Employee> getAllEmployee(){
List<Employee> list = new ArrayList<Employee>();
for(int i=0; i<30; i++){
Employee emp = new Employee();
//为总公司人员按顺序分配一个ID
emp.setId("总公司"+i);
list.add(emp);
}
return list;
}
public void printAllEmployee(SubCompanyManager sub){
List<SubEmployee> list1 = sub.getAllEmployee();
for(SubEmployee e:list1){
System.out.println(e.getId());
}
List<Employee> list2 = this.getAllEmployee();
for(Employee e:list2){
System.out.println(e.getId());
}
}
}
public class Client{
public static void main(String[] args){
CompanyManager e = new CompanyManager();
e.printAllEmployee(new SubCompanyManager());
}
}
问题所在:
现在这个设计的主要问题出在CompanyManager中,根据迪米特法则,只与直接的朋友发生通信,而SubEmployee类并不是CompanyManager类的直接朋友(以局部变量出现的耦合不属于直接朋友),从逻辑上讲总公司只与他的分公司耦合就行了,与分公司的员工并没有任何联系,这样设计显然是增加了不必要的耦合。按照迪米特法则,应该避免类中出现这样非直接朋友关系的耦合。修改后的代码如下:
修改后
class SubCompanyManager{
public List<SubEmployee> getAllEmployee(){
List<SubEmployee> list = new ArrayList<SubEmployee>();
for(int i=0; i<100; i++){
SubEmployee emp = new SubEmployee();
//为分公司人员按顺序分配一个ID
emp.setId("分公司"+i);
list.add(emp);
}
return list;
}
public void printEmployee(){
List<SubEmployee> list = this.getAllEmployee();
for(SubEmployee e:list){
System.out.println(e.getId());
}
}
}
class CompanyManager{
public List<Employee> getAllEmployee(){
List<Employee> list = new ArrayList<Employee>();
for(int i=0; i<30; i++){
Employee emp = new Employee();
//为总公司人员按顺序分配一个ID
emp.setId("总公司"+i);
list.add(emp);
}
return list;
}
public void printAllEmployee(SubCompanyManager sub){
sub.printEmployee();
List<Employee> list2 = this.getAllEmployee();
for(Employee e:list2){
System.out.println(e.getId());
}
}
}
修改后,为分公司增加了打印人员ID的方法,总公司直接调用来打印,从而避免了与分公司的员工发生耦合。 迪米特法则的初衷是降低类之间的耦合,由于每个类都减少了不必要的依赖,因此的确可以降低耦合关系。但是凡事都有度,虽然可以避免与非直接的类通信,但是要通信,必然会通过一个“中介”来发生联系,例如本例中,总公司就是通过分公司这个“中介”来与分公司的员工发生联系的。过分的使用迪米特原则,会产生大量这样的中介和传递类,导致系统复杂度变大。所以在采用迪米特法则时要反复权衡,既做到结构清晰,又要高内聚低耦合。
例子2:
现在市面上各种人脉书上很多都会提到“六度人脉”这个理论,这个理论说的是你与世界上任何一个人中间只隔了六个人。也就是说你想找任何一个人,无论这个人是政界要人,还是商界巨鳄,抑或是明星名人,你最多只通过六个人就可以联系到他(想想还有点小激动呢-_-#)。
我们暂且不论这个理论是对是错,在现实生活中我们也经常遇到这样的情况。比如你想办一件事情,但是凭借你的能力是做不到的,而你周围的朋友也无法帮你办到。但是恰好你有一个朋友认识有另外一个朋友可以办得成此事,那么你只有拜托你这位朋友中间牵线搭桥,让他的朋友帮你办好此事。
在这个例子中,我们就暂且定义你为A,你的朋友为B,你朋友的朋友为C好了。
反面教材
实现代码如下:
1.类A和类B是好朋友,能找到类B来帮忙:
public class A {
public String name;
public A(String name) {
this.name = name;
}
public B getB(String name) {
return new B(name);
}
public void work() {
B b = getB("李四");
C c = b.getC("王五");
c.work();
}
}
2.类B和类C是好朋友,能知道类C来帮忙:
public class B {
private String name;
public B(String name) {
this.name = name;
}
public C getC(String name) {
return new C(name);
}
}
3.类C能够办成此事:
public class C {
public String name;
public C(String name) {
this.name = name;
}
public void work() {
System.out.println(name + "把这件事做好了");
}
}
4.场景类
public class Client {
public static void main(String[] args) {
A a = new A("张三");
a.work();
}
}
运行结果如下:
王五把这件事做好了
上面的输出虽然是把事情成功办好了,但是仔细看业务逻辑明显是不对的。A和C又不是好朋友,为什么在类A中会出现类C呢?他们又互相不认识。
看到这里很多人都会明白,这种场景在实际开发中是非常常见的一种情况。对象A需要调用对象B的方法,对象B有需要调用对象C的方法……就是常见的getXXX().getXXX().getXXX()……类似于这种代码。如果你发现你的代码中也有这样的代码,那就考虑下是不是违反迪米特法则,是不是要重构一下了。
正确例子
为了符合迪米特法则,也为了让业务逻辑能够说得通,我们把上面的例子稍微修改一下。
代码如下:
1.类A和类B是好朋友,能找到类B来帮忙:
public class A {
public String name;
public A(String name) {
this.name = name;
}
public B getB(String name) {
return new B(name);
}
public void work() {
B b = getB("李四");
b.work();
}
}
2.类B和类C是好朋友,能知道类C来帮忙:
public class B {
private String name;
public B(String name) {
this.name = name;
}
public C getC(String name) {
return new C(name);
}
public void work(){
C c = getC("王五");
c.work();
}
}
3.类C能够办成此事:
public class C {
public String name;
public C(String name) {
this.name = name;
}
public void work() {
System.out.println(name + "把这件事做好了");
}
}
4.场景类
public class Client {
public static void main(String[] args) {
A a = new A("张三");
a.work();
}
}
运行结果如下:
王五把这件事做好了
上面代码只是修改了下类A和B的work方法,使之符合了迪米特法则:
- 类A只与最直接的朋友类B通信,不与类C通信;
- 类A只调用类B提供的方法即可,不用关心类B内部是如何实现的(至于B是怎么调用的C,这些A都不用关心)。
总结
迪米特法则的目的是让类之间解耦,降低耦合度。只有这样,类的可复用性才能提高。
但是迪米特法则也有弊端,它会产生大量的中转类或跳转类,导致系统的复杂度提高。
所以我们不要太死板的遵守这个迪米特法则,在系统设计的时候,在弱耦合和结构清晰之间反复权衡。尽量保证系统结构清晰,又能做到低耦合。
例子3:
这篇博客讲的很详细了,例子有点难
前面我们谈到了几种类与类之间的关系,现在我们来深入一下对象与对象之间的通信问题. 为什么要深入对象与对象之间的通信呢,其根本在于,系统中不会存在唯一的对象,不同的对象势必要相互进行交流.
初学者的问题
在我们刚开始学习编程的时候,通常会将所有的方法都声明为公有(public),但随着我们代码量的增加,我们都会遇到一个典型的问题:
在调用某个对象的方法时,我们发现编译器提示这个对象所有的方法,这意味着该对象处在不安全的状态。为什么这么说呢?如果我们将这个对象比作一个人,那么这个人在别人面前是赤裸的,没有任何隐私,这让别人有机会观察你的一切行为,并某刻致命一击。除此之外,这个完全暴露的人,也会让别人不知所措。
这显然不是我们想要的,因此我们需要某种机制来限制的对象信息的公开:哪些信息是可以公开的,哪些是不可以公开的,在java中,我们通过方法的权限来实现这一点,比如private修饰的方法只有对象自己内部可以调用,public修饰的方法是公开给其他对象的等。
现在,你可能已经明白,java的设计者为什么要“多此一举”的为方法设计权限了。那么有人会问,我该怎么确定哪个方法应该被设计成公有的,哪些又应该被设计成私有的呢?
当你心里有这个疑问的时候,说明你已经开始关注我们经常提到的面向对象编程的原则之一:封装,即如何划分对象的结构。 我们都知道对象的结构的可被划分为静态属性和动态属性,所谓的静态属性就是值对象固有的属性,比如任何一个生命体都有年龄,而动态属性也称为行为属性,指的是对象所表现出来的行为,比如袋鼠能跳,能呼吸等。而这静态属性和动态属性又可以细分为可公开的静态属性,可公开的动态属性等。也就是说,划分对象的结构实则就是确定某个对象的动态属性和静态属性,在此基础上再来确定属性是否可公开等。
不难发现,这个过程和我们的认知的思维过程很类似:大脑试图从各种各样的的物体中抽取特征。比如,我们看到猫,狗,仙人掌,为了能区分它们,我们的大脑会对这三者进行特征抽取,比如猫和狗都可以移动,有眼睛,会叫,有爪子,而仙人掌则是不可移动,有刺,不能叫等,通过这种特种抽取,我们能区分出动物和植物的区别。换言之,我们之所以能区分出不同的物体,都是因为我们的大脑已经默默的为我们做了特征抽取的工作,这个过程如果由我们主动去做就称之为抽象编程。
揭秘迪米特法则
迪米特法则(Law of demeter,缩写是LOD)要求:一个对象应该对其他对象保持最少了解, 通缩的讲就是一个类对自己依赖的类知道的越少越好,也就是对于被依赖的类,向外公开的方法应该尽可能的少。
迪米特法则还有一种解释:Only talk to your immediate friends,即只与直接朋友通信.首先来解释编程中的朋友:两个对象之间的耦合关系称之为朋友,通常有依赖,关联,聚合和组成等.而直接朋友则通常表现为关联,聚合和组成关系,即两个对象之间联系更为紧密,通常以成员变量,方法的参数和返回值的形式出现.
那么为什么说是要与直接朋友通信呢?观察直接朋友出现的地方,我们发现在直接朋友出现的地方,大部分情况下可以接口或者父类来代替,可以增加灵活性. (需要注意,在考虑这个问题的时候,我们只考虑新增的类,而忽视java为我们提供的基础类.)
实例演示
不难发现,迪米特法则强调了一下两点:
- 第一要义:从被依赖者的角度来说:只暴露应该暴露的方法或者属性,即在编写相关的类的时候确定方法/属性的权限
- 第二要义:从依赖者的角度来说,只依赖应该依赖的对象
先来解释第一点,我们使用计算机来说明,以关闭计算机为例:
当我们按下计算机的关机按钮的时候,计算机会执行一些列的动作会被执行:比如保存当前未完成的任务,然后是关闭相关的服务,接着是关闭显示器,最后是关闭电源,这一系列的操作以此完成后,计算机才会正式被关闭。
现在,我们来用简单的代码表示这个过程,在不考虑迪米特法则情况下,我们可能写出以下代码
//计算机类
public class Computer{
public void saveCurrentTask(){
//do something
}
public void closeService(){
//do something
}
public void closeScreen(){
//do something
}
public void closePower(){
//do something
}
public void close(){
saveCurrentTask();
closeService();
closeScreen();
closePower();
}
}
//人
public class Person{
private Computer c;
...
public void clickCloseButton(){
//现在你要开始关闭计算机了,正常来说你只需要调用close()方法即可,
//但是你发现Computer所有的方法都是公开的,该怎么关闭呢?于是你写下了以下关闭的流程:
c.saveCurrentTask();
c.closePower();
c.close();
//亦或是以下的操作
c.closePower();
//还可能是以下的操作
c.close();
c.closePower();
}
}
发现上面的代码中的问题了没? 我们观察clickCloseButton()方法,我们发现这个方法无法编写:c是一个完全暴露的对象,其方法是完全公开的,那么对于Person来说,当他想要执行关闭的时候,却发现不知道该怎么操作:该调用什么方法?靠运气猜么?如果Person的对象是个不按常理出牌的,那这个Computer的对象岂不是要被搞坏么?
迪米特法则第一要义
现在我们来看看迪米特法则的第一点:从被依赖者的角度,只应该暴露应该暴露的方法。那么这里的c对象应该哪些方法应该是被暴露的呢?很显然,对于Person来说,只需要关注计算机的关闭操作,而不关心计算机会如何处理这个关闭操作,因此只需要暴露close()方法即可。
那么上述的代码应该被修改为:
//计算机类
public class Computer{
private void saveCurrentTask(){
//do something
}
private void closeService(){
//do something
}
private void closeScreen(){
//do something
}
private void closePower(){
//do something
}
public void close(){
saveCurrentTask();
closeService();
closeScreen();
closePower();
}
}
//人
public class Person{
private Computer c;
...
public void clickCloseButton(){
c.close();
}
}
看一下它的类图:
这里写图片描述
接下来,我们继续来看迪米特法则的第二层含义:从依赖者的角度来说,只依赖应该依赖的对象。 这句话令人有点困惑,什么叫做应该依赖的对象呢?我们还是用上面“关闭计算机”的例子来说明: 准确的说,计算机包括操作系统和相关硬件,我们可以将其划分为System对象和Container对象。当我们关闭计算机的时候,本质上是向操作系统发出了关机指令,而实则我们只是按了一下关机按钮,也就是我们并没有依赖System的对象,而是依赖了Container。这里Container就是我们上面所说的直接朋友—只和直接朋友通信.
我们就这点,继续深入讨论一下:
only talk to your immedate friends
这句话只说明了要和直接朋友通信,但是我觉得这还不完整,我更愿意将其补充为:
make sure your friends,only talk to your immedate friends,don’t speak to strangers.
大意是:确定你真正的朋友,并只和他们通信,并且不要和陌生人讲话.这样做有个很大的好处就是,能够简化对象与对象之间的通信,进而减轻依赖,提供更高的灵活性,当然也可以提供一定的安全性.
现在来想想现实世界中的这么一种情况:你是一个令人瞩目的公众人物,周围的每个人都知道你的名字,当你独自走在大街上的时候会是怎么样的一种场景?每个人都想要和你聊天!,和你交换信息!!接着,你发现自己已经寸步难行了.如果这时候你有一个经纪人,来帮你应对周围的人,而你就只和这个经纪人通信,这样就大大减轻了你的压力,不是么?此时,这个经济人就相当于你的直接朋友.
迪米特法则第二要义
现在,我们再回顾”关机计算机”这个操作,前面的代码只是遵从了”暴漏应该暴漏的方法”这一点,现在我们结合第二点来进行改进:System和Container相比,System并非Person的直接朋友,而Container才是(Person直接打交道的是Container).因此我们需要将原有的Computer拆分成System和Cotainer,然后使Person只与Container通信,因此代码修改为:
//操作系统
public class System{
private void saveCurrentTask(){
//do something
}
private void closeService(){
//do something
}
private void closeScreen(){
//do something
}
private void closePower(){
//do something
}
public void close(){
saveCurrentTask();
closeService();
closeScreen();
closePower();
}
}
//硬件设备容器
public class Container{
private System mSystem;
public void sendCloseCommand(){
mSystem.close();
}
}
//人
ublic class Person{
private Container c;
....
public void clickCloseButton(){
c.sendCloseCommand();
}
}
来看一下它的类图:
重构,改善既有设计
在上文中,我们还提到,直接朋友出现的地方,我们可以采用其接口或者父类来代替.那么在这里,我们就可以为Container和System提供相应的接口
//System interface
public interface ISystem{
void close();
}
//System
public class System implements ISystem{
private void saveCurrentTask(){
//do something
}
private void closeService(){
//do something
}
private void closeScreen(){
//do something
}
private void closePower(){
//do something
}
@override
public void close(){
saveCurrentTask();
closeService();
closeScreen();
closePower();
}
}
//IContainer interface
public interface IContainer{
void sendCloseCommand();
}
//Contanier
public class Container implements IContainer{
private System mSystem;
@override
public void sendCloseCommand(){
mSystem.close();
}
}
//Person
ublic class Person{
private IContainer c;
....
public void clickCloseButton(){
c.sendCloseCommand();
}
}
来看一下它的类图:
对比这两种方案,明显这种方案二的解耦程度更高,灵活大大增强.不难发现,这应用了我们前面提到的依赖倒置,即面向接口编程.
除此之外,我们发现随着不断的改进,类的数量也在不断的增加,从2个增加到5个,这意味着为了解耦和提高灵活性通常要编写的类的数量会翻倍.因此,你需要在这做一个权衡,切莫刻意为了追求设计,而导致整个系统非常的冗余,最终可能得不偿失.
总结
有人会觉得Container像是一个中介(代理).没错,我们确实可以称其为中介,但这并不能否认他是我们的直接朋友:在很多情况下,中介可以说是我们的一种代表,因此将其定义为直接朋友是没有任何问题的.比如,当你想要租房的时候,你可以找房屋中介,对方会按照你的标准为你寻找合适的住房.但是问题来了:那么做一件事情需要多少中介呢?总不能是我委托一个中介A帮我找房子,但中介A又委托了中介B,中介B又委托了中介C….等等,如果真的是这样,那还不如我自己去找房子效率更高.在实际开发中,委托的层次要控制在6层以下,多余6层以上的会使得系统过分的冗余和并切会委托层次过多而导致开发人员无法正确的理解流程,产生风险的可能会大大提高.
到目前,我们已经彻底的了解了迪米特法则.
作者:涅槃1992
链接:https://www.jianshu.com/p/30931aab5ea0
來源:简书
二、降低继承耦合
里氏替换原则
这项原则最早是在1988年,由麻省理工学院的一位姓里的女士(Barbara Liskov)提出来的。
定义1:如果对每一个类型为 T1的对象 o1,都有类型为 T2 的对象o2,使得以 T1定义的所有程序 P 在所有的对象 o1 都代换成 o2 时,程序 P 的行为没有发生变化,那么类型 T2 是类型 T1 的子类型。
定义2:所有引用基类的地方必须能透明地使用其子类的对象。
问题由来:有一功能P1,由类A完成。现需要将功能P1进行扩展,扩展后的功能为P,其中P由原有功能P1与新功能P2组成。新功能P由类A的子类B来完成,则子类B在完成新功能P2的同时,有可能会导致原有功能P1发生故障。
解决方案:当使用继承时,遵循里氏替换原则。类B继承类A时,除添加新的方法完成新增功能P2外,尽量不要重写父类A的方法,也尽量不要重载父类A的方法。
例子1:
class A{
public int func1(int a, int b){
return a-b;
}
}
public class Client{
public static void main(String[] args){
A a = new A();
System.out.println("100-50="+a.func1(100, 50));
System.out.println("100-80="+a.func1(100, 80));
}
}
运行结果:
100-50=50
100-80=20
后来,我们需要增加一个新的功能:完成两数相加,然后再与100求和,由类B来负责。即类B需要完成两个功能:
- 两数相减。
- 两数相加,然后再加100。
由于类A已经实现了第一个功能,所以类B继承类A后,只需要再完成第二个功能就可以了,代码如下:
class B extends A{
public int func1(int a, int b){
return a+b;
}
public int func2(int a, int b){
return func1(a,b)+100;
}
}
public class Client{
public static void main(String[] args){
B b = new B();
System.out.println("100-50="+b.func1(100, 50));
System.out.println("100-80="+b.func1(100, 80));
System.out.println("100+20+100="+b.func2(100, 20));
}
}
运行结果:
100-50=150
100-80=180
100+20+100=220
我们发现原本运行正常的相减功能发生了错误。原因就是类B在给方法起名时无意中重写了父类的方法,造成所有运行相减功能的代码全部调用了类B重写后的方法,造成原本运行正常的功能出现了错误。在本例中,引用基类A完成的功能,换成子类B之后,发生了异常。在实际编程中,我们常常会通过重写父类的方法来完成新的功能,这样写起来虽然简单,但是整个继承体系的可复用性会比较差,特别是运用多态比较频繁时,程序运行出错的几率非常大。如果非要重写父类的方法,比较通用的做法是:原来的父类和子类都继承一个更通俗的基类,原有的继承关系去掉,采用依赖、聚合,组合等关系代替。
里氏替换原则通俗的来讲就是:子类可以扩展父类的功能,但不能改变父类原有的功能。它包含以下4层含义:
- 子类可以实现父类的抽象方法,但不能覆盖父类的非抽象方法。
- 子类中可以增加自己特有的方法。
- 当子类的方法重载父类的方法时,方法的前置条件(即方法的形参)要比父类方法的输入参数更宽松。
- 当子类的方法实现父类的抽象方法时,方法的后置条件(即方法的返回值)要比父类更严格。
看上去很不可思议,因为我们会发现在自己编程中常常会违反里氏替换原则,程序照样跑的好好的。所以大家都会产生这样的疑问,假如我非要不遵循里氏替换原则会有什么后果?
后果就是:你写的代码出问题的几率将会大大增加。
例子2:
参考网址:https://blog.csdn.net/yuanlong_zheng/article/details/7425919
1.定义:Functions that use pointers or referrnces to base classes must be able to use objects of derived classes without knowing it.(所有引用基类的地方必须能透明地使用其子类的对象。)
2.理解:只要父类能出现的地方,子类就可以出现,并且替换为子类也不会产生任何错误或异常,使用者可能根本就不需要知道是父类还是子类。但反之,未要求。
继承机制的优点:
- 代码共享,减少创建类的工作量;
- 提高代码的重用性;
- 子类可以形似父类,又异于父类;
- 提高父类的扩展性,实现父类的方法即可随意而为;
- 提高产品或项。
继承机制的缺点:
- 继承是入侵性的(只要继承,就必须拥有父类的所有属性与方法);
- 降低了代码的灵活性(子类拥有了父类的属性方法,会增多约束);
- 增强了耦合性(当父类的常量、变量、方法被修改时,必需要考虑子类的修改)。
定义所包含的四层意思:(另一种通俗的LSP原则讲解:子类可以扩展父类的功能,但不能改变父类原有的功能)
- 子类可以实现父的抽象方法,但不能覆盖父类的非抽象方法(做系统设计时,经常会定义一个接口或抽象类,然后编码实现(定义的方法或接口),调用类则直接传入接口或抽象类,这里也是LSP的应用体现);
- 子类可以有自己的方法和属性(因为LSP可以正用,不能反用:在子类出现的地方,父类未必就可以胜任(本来就无此要求)。即不要死扣——所有的地方(如参数)都要以父类的形式出现(再作转化),实现中有需要依赖子类的情况,这是正常的);
- 覆盖或实现父类的方法时输入参数可以被放大(放大的实质为重载,因为参数不同;为什么只能放大?因为父类方法的参数类型相对较小,所以当传入父类方法的参数类型(或更窄类型)时,重载时,将优先匹配父类的方法,因此子类重载的方法并不会对此参数类型被执行,因此保证了LSP,且不会引起想不到的业务逻辑混乱。若为覆写,则程序员必清楚其逻辑要义);
- 覆写或实现父类的方法时输出结果可以被缩小(若放大,还能用子类替换父类吗?)。
Liskov替换原则并不是要求子类不能新增父类没有的方法或者属性。因为从调用父类的客户程序的角度来说,它关心的仅仅是父类的行为,只要子类对于父类的行为是可替换的,就不算是违背该原则。
恰恰相反,当你发现父类拥有子类不希望继承,或者勉强继承会对子类造成破坏时 ,正可以说明这个继承体系可能存在问题,违背了Liskov替换原则。这就充分说明,子类并不关心父类的行为,但却需要遵循父类制定的规范或契约,以满足客户调用父类的期望。正所谓”萧规曹随”,如果前人制定的规范我们不遵循,反而要去打破,那就不是继承,而是铁了心要另起炉灶了。 一个经典的违反Liskov替换原则的例子是正方形与矩形之间的关系。这样的例子在谈对象设计的原则时,已经啰嗦得够多,这里我就不再赘述了 。这个例子带来的教训就是,现实世界中继承的例子,不能够完全直接套用在程序世界中。不过,作为设计的参照物,现实世界的很多规律与法则,我们仍然不可忽视。例如鲸鱼和鱼,应该属于什么关系?从生物学的角度看,鲸鱼应该属于哺乳动物,而不是鱼类。
3.问题由来
有一功能P1,由类A完成。现需要将功能P1进行扩展,扩展后的功能为P,其中P由原有功能P1与新功能P2组成。新功能P由类A的子类B来完成,则子类B在完成新功能P2的同时,有可能会导原有功能P1发生故障。解决方案:遵循LSP:类B在继承类A时,除添加新的方法完成新增功能P2外,尽量不要重写父类A的方法,也尽量不要重载父类的A的方法。
4.好处
即为正确使用继承的好处。
5.难点
5.1 如何根据类的继承原则,确定是要继承当前类结构,还是要另起炉赵。
5.2 如何根据情况,在违背Liskov替换原则时,提出一种方案。
6.实践建议
6.1 在类中调用其它类时务必要使用父类或接口,如果不能使用父类或接口,则说明类的设计已违背了LSP;(例:Interface in = new Instance(););
6.2 如果子类不能完整地实现父类的方法,或者父类的某些方法在子类中已经发生“畸变”,则建议断开父子继承关系,采用依赖、聚集、组合等关系代替继承。
6.3 如果你的程序中出现了if/else之类对子类类型进行判断的条件,则说明类的设计已违背了LSP。
7.范例
7.1 矩形与正方形(现实中的继承,却不能直接用于程序中)
对于长方形的类,如果它的长宽相等,那么它就是一个正方形,因此,长方形类的对象中有一些正方形的对象。对于一个正方形的类,它的方法有个setSide和getSide,它不是长方形的子类,和长方形也不会符合LSP。
//长方形类:
public class Rectangle{
...
setWidth(int width){
this.width=width;
}
setHeight(int height){
this.height=height
}
}
//正方形类:
public class Square{
...
setWidth(int width){
this.width=width;
this. height=width;
}
setHeight(int height){
this.setWidth(height);
}
}
//例子中改变边长的方法:
public void resize(Rectangle r){
while(r.getHeight()<=r.getWidth){
r.setHeight(r.getWidth+1);
}
}
那么,如果让正方形当做是长方形的子类,会出现什么情况呢?我们让正方形从长方形继承,然后在它的内部设置width等于height,这样,只要width或者height被赋值,那么width和height会被同时赋值,这样就保证了正方形类中,width和height总是相等的.现在我们假设有个客户类,其中有个方法,规则是这样的,测试传入的长方形的宽度是否大于高度,如果满足就停止下来,否则就增加宽度的值。现在我们来看,如果传入的是基类长方形,这个运行的很好。根据LSP,我们把基类替换成它的子类,结果应该也是一样的,但是因为正方形类的width和height会同时赋值,这个方法没有结束的时候,条件总是不满足,也就是说,替换成子类后,程序的行为发生了变化,它不满足LSP。
7.2 鲸鱼与鱼(避开违背LSP的一种解决方案)
鲸鱼和鱼,应该属于什么关系?从生物学的角度看,鲸鱼应该属于哺乳动物,而不是鱼类。没错,在程序世界中我们可以得出同样的结论。如果让鲸鱼类去继承鱼类,就完全违背了Liskov替换原则。因为鱼作为父类,很多特性是鲸鱼所不具备的,例如通过腮呼吸,以及卵生繁殖。那么,二者是否具有共性呢?有,那就是它们都可以在水中”游泳”,从程序设计的角度来说,它们都共同实现了一个支持”游泳”行为的接口。 如下所示的设计,可以看做是解决违背Liskov替换原则的一种常规方案,即提取两者之间的共同点,定义一个更为通用的接口,或者新的父类。

7.3 继承的风险
举例说明继承的风险,我们需要完成一个两数相减的功能,由类A来负责:
class A{
public int func1(int a, int b){
return a-b;
}
}
public class Client{
public static void main(String[] args){
A a = new A();
System.out.println("100-50="+a.func1(100, 50));
System.out.println("100-80="+a.func1(100, 80));
}
}
运行结果:
100-50=50
100-80=20
后来,我们需要增加一个新的功能:完成两数相加,然后再与100求和,由类B来负责。即类B需要完成两个功能:
- 两数相减
- 两数相加,再加100
由于类A已经实现了第一个功能,所以类B继承类A后,只需要再完成第二个功能就可以了,代码如下:
class B extends A{
public int func1(int a, int b){
return a+b;
}
public int func2(int a, int b){
return func1(a,b)+100;
}
}
public class Client{
public static void main(String[] args){
B a = new B();
System.out.println("100-50="+b.func1(100, 50));
System.out.println("100-80="+b.func1(100, 80));
System.out.println("100+20+100="+b.func2(100, 20));
}
}
运行结果:
100-50=150
100-80=180
100+20+100=220
我们发现原来运行正常的相减功能发生了错误。原因就是类B在给方法起名时无意中重写了父类的方法,造成所有运行相减功能的代码全部调用了类B的重写后的方法,造成原本运行正常的功能出现了错误。
其他参考网址:
https://juejin.im/post/5a31ecedf265da43346fed08
三、提高内聚
单一职责原则
定义:不要存在多于一个导致类变更的原因。通俗的说,即一个类只负责一项职责。
问题由来:类T负责两个不同的职责:职责P1,职责P2。当由于职责P1需求发生改变而需要修改类T时,有可能会导致原本运行正常的职责P2功能发生故障。
解决方案:遵循单一职责原则。分别建立两个类T1、T2,使T1完成职责P1功能,T2完成职责P2功能。这样,当修改类T1时,不会使职责P2发生故障风险;同理,当修改T2时,也不会使职责P1发生故障风险。
说到单一职责原则,很多人都会不屑一顾。因为它太简单了。稍有经验的程序员即使从来没有读过设计模式、从来没有听说过单一职责原则,在设计软件时也会自觉的遵守这一重要原则,因为这是常识。在软件编程中,谁也不希望因为修改了一个功能导致其他的功能发生故障。而避免出现这一问题的方法便是遵循单一职责原则。虽然单一职责原则如此简单,并且被认为是常识,但是即便是经验丰富的程序员写出的程序,也会有违背这一原则的代码存在。为什么会出现这种现象呢?因为有职责扩散。所谓职责扩散,就是因为某种原因,职责P被分化为粒度更细的职责P1和P2。
比如:类T只负责一个职责P,这样设计是符合单一职责原则的。后来由于某种原因,也许是需求变更了,也许是程序的设计者境界提高了,需要将职责P细分为粒度更细的职责P1,P2,这时如果要使程序遵循单一职责原则,需要将类T也分解为两个类T1和T2,分别负责P1、P2两个职责。但是在程序已经写好的情况下,这样做简直太费时间了。所以,简单的修改类T,用它来负责两个职责是一个比较不错的选择,虽然这样做有悖于单一职责原则。(这样做的风险在于职责扩散的不确定性,因为我们不会想到这个职责P,在未来可能会扩散为P1,P2,P3,P4……Pn。所以记住,在职责扩散到我们无法控制的程度之前,立刻对代码进行重构。)
例子1:
class Animal{
public void breathe(String animal){
System.out.println(animal+"呼吸空气");
}
}
public class Client{
public static void main(String[] args){
Animal animal = new Animal();
animal.breathe("牛");
animal.breathe("羊");
animal.breathe("猪");
}
}
运行结果:
牛呼吸空气
羊呼吸空气
猪呼吸空气
程序上线后,发现问题了,并不是所有的动物都呼吸空气的,比如鱼就是呼吸水的。修改时如果遵循单一职责原则,需要将Animal类细分为陆生动物类Terrestrial,水生动物Aquatic,代码如下:
class Terrestrial{
public void breathe(String animal){
System.out.println(animal+"呼吸空气");
}
}
class Aquatic{
public void breathe(String animal){
System.out.println(animal+"呼吸水");
}
}
public class Client{
public static void main(String[] args){
Terrestrial terrestrial = new Terrestrial();
terrestrial.breathe("牛");
terrestrial.breathe("羊");
terrestrial.breathe("猪");
Aquatic aquatic = new Aquatic();
aquatic.breathe("鱼");
}
}
运行结果:
牛呼吸空气
羊呼吸空气
猪呼吸空气
鱼呼吸水
我们会发现如果这样修改花销是很大的,除了将原来的类分解之外,还需要修改客户端。而直接修改类Animal来达成目的虽然违背了单一职责原则,但花销却小的多,代码如下:
class Animal{
public void breathe(String animal){
if("鱼".equals(animal)){
System.out.println(animal+"呼吸水");
}else{
System.out.println(animal+"呼吸空气");
}
}
}
public class Client{
public static void main(String[] args){
Animal animal = new Animal();
animal.breathe("牛");
animal.breathe("羊");
animal.breathe("猪");
animal.breathe("鱼");
}
}
可以看到,这种修改方式要简单的多。但是却存在着隐患:有一天需要将鱼分为呼吸淡水的鱼和呼吸海水的鱼,则又需要修改Animal类的breathe方法,而对原有代码的修改会对调用“猪”“牛”“羊”等相关功能带来风险,也许某一天你会发现程序运行的结果变为“牛呼吸水”了。这种修改方式直接在代码级别上违背了单一职责原则,虽然修改起来最简单,但隐患却是最大的。还有一种修改方式:
class Animal{
public void breathe(String animal){
System.out.println(animal+"呼吸空气");
}
public void breathe2(String animal){
System.out.println(animal+"呼吸水");
}
}
public class Client{
public static void main(String[] args){
Animal animal = new Animal();
animal.breathe("牛");
animal.breathe("羊");
animal.breathe("猪");
animal.breathe2("鱼");
}
}
可以看到,这种修改方式没有改动原来的方法,而是在类中新加了一个方法,这样虽然也违背了单一职责原则,但在方法级别上却是符合单一职责原则的,因为它并没有动原来方法的代码。这三种方式各有优缺点,那么在实际编程中,采用哪一中呢?其实这真的比较难说,需要根据实际情况来确定。我的原则是:只有逻辑足够简单,才可以在代码级别上违反单一职责原则;只有类中方法数量足够少,才可以在方法级别上违反单一职责原则;
例如本文所举的这个例子,它太简单了,它只有一个方法,所以,无论是在代码级别上违反单一职责原则,还是在方法级别上违反,都不会造成太大的影响。实际应用中的类都要复杂的多,一旦发生职责扩散而需要修改类时,除非这个类本身非常简单,否则还是遵循单一职责原则的好。
遵循单一职责原的优点有:
- 可以降低类的复杂度,一个类只负责一项职责,其逻辑肯定要比负责多项职责简单的多;
- 提高类的可读性,提高系统的可维护性;
- 变更引起的风险降低,变更是必然的,如果单一职责原则遵守的好,当修改一个功能时,可以显著降低对其他功能的影响。
需要说明的一点是单一职责原则不只是面向对象编程思想所特有的,只要是模块化的程序设计,都适用单一职责原则。
例子2:
一职责原则是最简单的面向对象设计原则,它用于控制类的粒度大小。单一职责原则定义如下: 单一职责原则(Single Responsibility Principle, SRP):一个类只负责一个功能领域中的相应职责,或者可以定义为:就一个类而言,应该只有一个引起它变化的原因。
单一职责原则告诉我们:一个类不能太“累”!在软件系统中,一个类(大到模块,小到方法)承担的职责越多,它被复用的可能性就越小,而且一个类承担的职责过多,就相当于将这些职责耦合在一起,当其中一个职责变化时,可能会影响其他职责的运作,因此要将这些职责进行分离,将不同的职责封装在不同的类中,即将不同的变化原因封装在不同的类中,如果多个职责总是同时发生改变则可将它们封装在同一类中。
单一职责原则是实现高内聚、低耦合的指导方针,它是最简单但又最难运用的原则,需要设计人员发现类的不同职责并将其分离,而发现类的多重职责需要设计人员具有较强的分析设计能力和相关实践经验。
下面通过一个简单实例来进一步分析单一职责原则:
Sunny软件公司开发人员针对某CRM(Customer Relationship Management,客户关系管理)系统中客户信息图形统计模块提出了如图1所示初始设计方案:
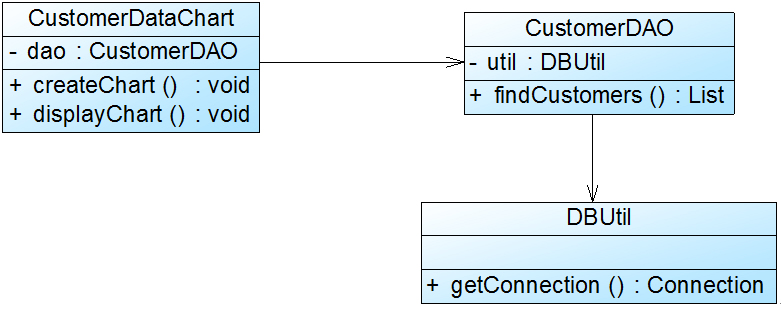
图1 初始设计方案结构图

在图1中,CustomerDataChart类中的方法说明如下:getConnection()方法用于连接数据库,findCustomers()用于查询所有的客户信息,createChart()用于创建图表,displayChart()用于显示图表。
现使用单一职责原则对其进行重构。
在图1中,CustomerDataChart类承担了太多的职责,既包含与数据库相关的方法,又包含与图表生成和显示相关的方法。如果在其他类中也需要连接数据库或者使用findCustomers()方法查询客户信息,则难以实现代码的重用。无论是修改数据库连接方式还是修改图表显示方式都需要修改该类,它不止一个引起它变化的原因,违背了单一职责原则。因此需要对该类进行拆分,使其满足单一职责原则,类CustomerDataChart可拆分为如下三个类:
(1) DBUtil:负责连接数据库,包含数据库连接方法getConnection();
(2) CustomerDAO:负责操作数据库中的Customer表,包含对Customer表的增删改查等方法,如findCustomers();
(3) CustomerDataChart:负责图表的生成和显示,包含方法createChart()和displayChart()。
使用单一职责原则重构后的结构如图2所示:
例子3:
单一职责原则的英文名称是Single Responsibility Principle,简称是SRP。这个设计原则备受争议,只要你想和别人争执、怄气或者是吵架,这个原则是屡试不爽的。如果你是老大,看到一个接口或类是这样或那样设计的,你就问一句:“你设计的类符合SRP原则吗?”保准对方立马“萎缩”掉,而且还一脸崇拜地看着你,心想:“老大确实英明”。这个原则存在争议之处在哪里呢?就是对职责的定义,什么是类的职责,以及怎么划分类的职责。我们先举个例子来说明什么是单一职责原则。
只要做过项目,肯定要接触到用户、机构、角色管理这些模块,基本上使用的都是RBAC模型(Role-Based Access Control,基于角色的访问控制,通过分配和取消角色来完成用户权限的授予和取消,使动作主体(用户)与资源的行为(权限)分离),确实是一个很好的解决办法。我们这里要讲的是用户管理、修改用户的信息、增加机构(一个人属于多个机构)、增加角色等,用户有这么多的信息和行为要维护,我们就把这些写到一个接口中,都是用户管理类嘛,我们先来看它的类图,如图1-1所示。

图1-1 用户信息维护类图
太Easy的类图了,我相信,即使是一个初级的程序员也可以看出这个接口设计得有问题,用户的属性和用户的行为没有分开,这是一个严重的错误!这个接口确实设计得一团糟,应该把用户的信息抽取成一个BO(Business Object,业务对象),把行为抽取成一个Biz(Business Logic,业务逻辑),按照这个思路对类图进行修正,如图1-2所示。

图1-2 职责划分后的类图
重新拆封成两个接口,IUserBO负责用户的属性,简单地说,IUserBO的职责就是收集和反馈用户的属性信息;IUserBiz负责用户的行为,完成用户信息的维护和变更。各位可能要说了,这个与我实际工作中用到的User类还是有差别的呀!别着急,我们先来看一看分拆成两个接口怎么使用。OK,我们现在是面向接口编程,所以产生了这个UserInfo对象之后,当然可以把它当IUserBO接口使用。也可以当IUserBiz接口使用,这要看你在什么地方使用了。要获得用户信息,就当是IUserBO的实现类;要是希望维护用户的信息,就把它当作IUserBiz的实现类就成了,如代码清单1-1所示。
代码清单1-1 分清职责后的代码示例
......
IUserInfo userInfo = new UserInfo();
//我要赋值了,我就认为它是一个纯粹的BO
IUserBO userBO = (IUserBO)userInfo;
userBO.setPassword("abc");
//我要执行动作了,我就认为是一个业务逻辑类
IUserBiz userBiz = (IUserBiz)userInfo;
userBiz.deleteUser();
......
确实可以如此,问题也解决了,但是我们来分析一下刚才的动作,为什么要把一个接口拆分成两个呢?其实,在实际的使用中,我们更倾向于使用两个不同的类或接口:一个是IUserBO,一个是IUserBiz,类图如图1-3所示。

图1-3 项目中经常采用的SRP类图
以上我们把一个接口拆分成两个接口的动作,就是依赖了单一职责原则,那什么是单一职责原则呢?单一职责原则的定义是:应该有且仅有一个原因引起类的变更。
例子4:
一、定义
单一职责原则(Single Responsibility Principle)的定义是:一个类,应该只有一个引起它变化的原因。说白了,就是让一个类只负责一件事,将关联性强的内容聚合到一个类中。
二、代码示例
首先我们有一个用户信息类(接口)(IUserInfo.java)
public interface IUserInfo {
void getId();
void setId(int id);
void getName();
void setName(String name);
void getPassword();
void setPassword(String password);
void addUser(int id, String name, String password);
void deleteUser(int id);
}
复制代码
下面是它的UML图:
看到上面的代码,很多人可能就说了,这个代码有问题啊,怎么可以将业务对象和业务逻辑的内容放到一个类中,业务对象和业务逻辑都会引起IUserInfo类的变化,上面的代码就违反了单一职责原则。 那我们按照单一职责的要求,我们要怎么改呢?那就是让一个类只做一件事,我们对上面的代码做如下的变化:
public interface IUserBo {
void getId();
void setId(int id);
void getName();
void setName(String name);
void getPassword();
void setPassword(String password);
}
复制代码
public interface IUserBiz {
void addUser(int id, String name, String password);
void deleteUser(int id);
}
复制代码
上面,我们将IUserInfo拆分为了IUserBo 和 IUserBiz,然后让IUserBiz在适当时候去操作IUserBo即可。 经过上面的修改,我们就实现了两个类的单一职责,也就是让引起他们变化原因只有一种,并且让相关性强的内容聚合在一个类内部。
三、优点
通过上面简单的例子,我们来总结一下单一职责原则的优点
1 . 类的复杂性降低,由于我们让每个类的职责单一,这样每个类职责清楚,定义明确
2 . 可读性提高了,复杂性降低了,类更便于维护
3 . 变更的风险降低了,需求一直在变,使用单一职责,只需要修改一个接口及其实现类,对其他类和接口没有影响
四、疑惑
看了上面的内容,可能有人觉得例子这么简单,而且说了半天貌似只是接口职责单一,类的职责并不是单一的。对,确实是这样。 首先,对于职责的划分这个是人为因素,可能每个人都有不同的看法,这种划分没有一个标准答案,因项目和环境而异。我们只需要尽量让一个类的职责清楚,让引起这个类变化的原因只有一个即可。但其实总是很难做到的,随着项目经验的增加,可能才会让我们设计的类越来越完善。我们要保证接口职责单一,类的职责尽量单一即可。
作者:冰鉴IT
链接:https://juejin.im/post/5a31db5df265da430406a096
来源:掘金
其他参考网址:
http://blog.jobbole.com/99587/
http://www.infoq.com/cn/articles/single-responsibility-in-software-development




