
文书分类问题介绍
参考网址:http://www.blogjava.net/zhenandaci/archive/2008/05/31/205089.html
https://zhuanlan.zhihu.com/p/25928551
1. 文本分类方法
文本分类问题与其它分类问题没有本质上的区别,其方法可以归结为根据待分类数据的某些特征来进行匹配。
因此核心的问题便转化为用哪些特征表示一个文本才能保证有效和快速的分类(注意这两方面的需求往往是互相矛盾的)
最早的词匹配法仅仅根据文档中是否出现了与类名相同的词(顶多再加入同义词的处理)来判断文档是否属于某个类别。很显然,这种过于简单的方法无法带来良好的分类效果。
后来兴起过一段时间的知识工程的方法则借助于专业人员的帮助,为每个类别定义大量的推理规则,如果一篇文档能满足这些推理规则,则可以判定属于该类别。这里与特定规则的匹配程度成为了文本的特征。甚至在80年代初一度发展到利用知识工程建立专家系统,这样做的好处是短平快的解决top问题,但显然天花板非常低,不仅费时费力,覆盖的范围和准确率都非常有限。
后来伴随着统计学习方法的发展,特别是90年代后互联网在线文本数量增长和机器学习学科的兴起,逐渐形成了一套解决大规模文本分类问题的经典玩法,这个阶段的主要套路是人工特征工程+浅层分类模型。训练文本分类器过程见下图:
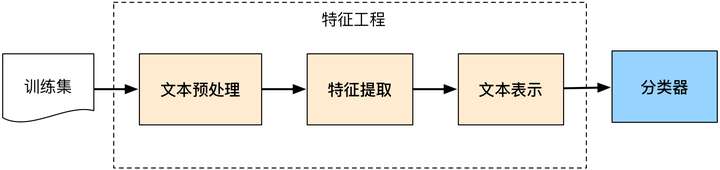
后来人们意识到,究竟依据什么特征来判断文本应当隶属的类别这个问题,就连人类自己都不太回答得清楚,有太多所谓“只可意会,不能言传”的东西在里面。人类的判断大多依据经验以及直觉,因此自然而然的会有人想到何让机器像人类一样自己来通过对大量同类文档的观察来自己总结经验,作为今后分类的依据。 这便是统计学习方法的基本思想(也有人把这一大类方法称为机器学习,两种叫法只是涵盖范围大小有些区别,均无不妥)。
1.1 特征工程
特征工程在机器学习中往往是最耗时耗力的,但却极其的重要。抽象来讲,机器学习问题是把数据转换成信息再提炼到知识的过程,特征是“数据–>信息”的过程,决定了结果的上限,而分类器是“信息–>知识”的过程,则是去逼近这个上限。然而特征工程不同于分类器模型,不具备很强的通用性,往往需要结合对特征任务的理解。
文本分类问题所在的自然语言领域自然也有其特有的特征处理逻辑,传统分本分类任务大部分工作也在此处。文本特征工程分位文本预处理、特征提取、文本表示三个部分,最终目的是把文本转换成计算机可理解的格式,并封装足够用于分类的信息,即很强的特征表达能力。
1)文本预处理
- 文本中提取关键词表示文本的过程,中文文本处理包括文本分词和去停用词
- 进行分词是因为研究表明特征粒度为词粒度好于字粒度(大部分分类算法不考虑词序信息,基于字粒度损失了过多n-gram)
2)文本表示和特征提取
文本表示:
-
目的是将文本预处理后的转换成计算机可以理解的方式,是决定文本分类质量最重要的部分。
-
词袋模型BOW,Bag Of Words
存在问题:高纬度,高稀疏性
是量空间模型的基础,因此向量空间模型通过特征项选择降低维度,通过特征权重计算增加稠密性。
( 0, 0, 0, 0, .... , 1, ... 0, 0, 0, 0) -
向量空间模型 Vector Space Model
存在问题:忽略上下文关系,每个词之间彼此独立,无法表征语义信息
特征提取:
向量空间模型包括:
1. 特征项的选择
2. 特征权重计算
特征选择的基本思路是根据某个评价指标独立的对原始特征项(词项)进行评分排序,从中选择得分最高的一些特征项,过滤掉其余的特征项。常用的评价有文档频率、互信息、信息增益、χ²统计量等。
3)基于语义的文本表示
1. LDA主题模型
2. LSI/PLSI概率潜在语义索引
1.2 分类器
- 朴素贝叶斯
- KNN
- SVM
- 最大熵
- 神经网络
二、深度学习文本分类方法
上文介绍了传统的文本分类做法,传统做法主要问题的文本表示是高纬度高稀疏的,特征表达能力很弱,而且神经网络很不擅长对此类数据的处理;此外需要人工进行特征工程,成本很高。而深度学习最初在之所以图像和语音取得巨大成功,一个很重要的原因是图像和语音原始数据是连续和稠密的,有局部相关性。应用深度学习解决大规模文本分类问题最重要的是解决文本表示,再利用CNN/RNN等网络结构自动获取特征表达能力,去掉繁杂的人工特征工程,端到端的解决问题。接下来会分别介绍:
2.1 文本的分布式表示:词向量(word embedding)
发展历程:
- Hinton 86年就提出了词的分布式表示;
- Bengio 03年便提出了NNLM
下图是03年Bengio在 A Neural Probabilistic Language Model的网络结构:
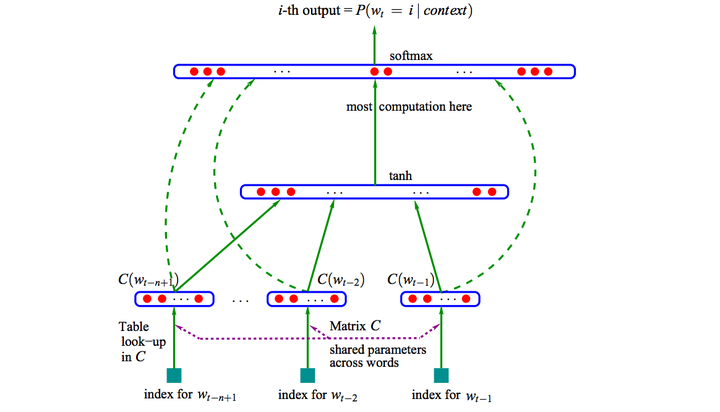
这篇文章提出的神经网络语言模型(NNLM,Neural Probabilistic Language Model)采用的是文本分布式表示,即每个词表示为稠密的实数向量。NNLM模型的目标是构建语言模型:
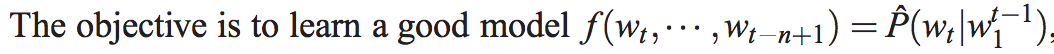
词的分布式表示即词向量(word embedding)是训练语言模型的一个附加产物,即图中的Matrix C。
-
真正火起来是google Mikolov 13年发表的两篇word2vec的文章 Efficient Estimation of Word Representations in Vector Space 和 Distributed Representations of Words and Phrases and their Compositionality,更重要的是发布了简单好用的word2vec工具包,在语义维度上得到了很好的验证,极大的推进了文本分析的进程。
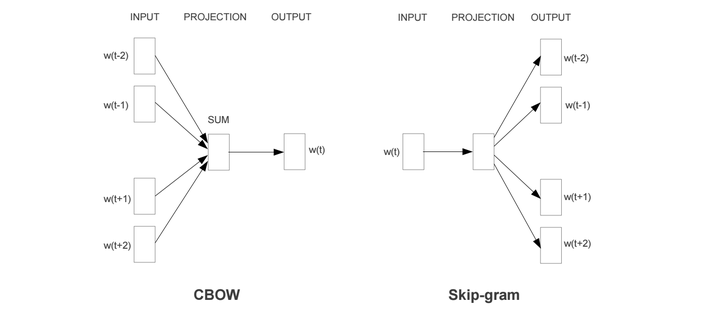
文中提出两个模型
- CBOW
- Skip-Gram
各种机器学习分类模型的优缺点
KNN: 依赖数据,无数学模型可言。适用于可容易解释的模型。 对异常值敏感,容易受到数据不平衡的影响。
Bayesian: 基于条件概率, 适用于不同维度之间相关性较小的时候,比较容易解释。也适合增量训练,不必要再重算一遍。应用:垃圾邮件处理。
Decision Tree: 此模型更容易理解不同属性对于结果的影响程度(如在第几层)。可以同时处理不同类型的数据。但因为追踪结果只需要改变叶子节点的属性,所以容易受到攻击。应用:其他算法的基石。
Random Forest: 随机森林是决策树的随机集成,一定程度上改善了其容易被攻击的弱点。适用于数据维度不太高(几十)又想达到较高准确性的时候。不需要调整太多参数,适合在不知道适用什么方法的时候先用下。
SVM: SVM尽量保持样本间的间距,抗攻击能力强,和RandomForest一样是一个可以首先尝试的方法。
对数几率回归:Logistic regression,不仅可以输出结果还可以输出其对应的概率。拟合出来的参数可以清晰地看到每一个feature对结果的影响。但是本质上是一个线性分类器,特征之间相关度高时不适用。同时也要注意异常值的的影响。
Discriminat Analysis典型的是LDA,把高维数据投射到低维上,使数据尽可能分离。往往作为一个降维工具使用。但是注意LDA假设数据是正态分布的。
Neural Network. 准确来说还是一个黑箱,适用于数据量大的时候使用。
Ensemble-Boosting : 每次寻找一个可以解决当前错误的分类器,最后再通过权重加和。好处是自带了特征选择,发现有效的特征。也方便去理解高维数据。
Ensemble-Bagging: 训练多个弱分类器投票解决。随机选取训练集,避免了过拟合。
Ensemble-Stacking: 以分类器的结果为输入,再训练一个分类器。一般最后一层用logistic Regression. 有可能过渡拟合,很少使用。
其他:
Maximum entropy model 最大熵模型不是一个分类器,是用来判断预测结果好坏的。对于它来说,分类器预测是相当于是:针对样本,给每个类一个出现概率。比如说样本的特征是:性别男。我的分类器可能就给出了下面这样一个概率:高(60%),矮(40%)。 而如果这个样本真的是高的,那我们就得了一个分数60%。最大熵模型的目标就是让这些分数的乘积尽量大。 决策树的数学基础就是他。 LR其实就是使用最大熵模型作为优化目标的一个算法
Expactation-Maximization EM也不是分类器,而是一个思路,很多算法基于此实现。如高斯混合模型,k-means聚类
Hidden Markov Model 马尔科夫模型不是一个分类器,主要用于通过前面的状态预测后面的状态。主要作用与序列。用于语音识别效果较好。
Reference:
Fernández-Delgado, Manuel, et al. J. Mach. Learn. Res 15.1 (2014) [2]: An empirical evaluation of supervised learning in high dimensions. Rich Caruana, Nikos Karampatziakis, and Ainur Yessenalina. ICML ‘08
整理自: 1 https://www.zhihu.com/question/26726794 [2] https://static.coggle.it/diagram/WHeBqDIrJRk-kDDY/t/categories-of-algorithms-non-exhaustive
法律文书常见种类
民商裁决文书、行政裁决文书、刑事裁决文书、仲裁法律文书、公证法律文书
诉讼法律文书、非诉法律文书、公司管理文书、公司清算文书、常用法律文书
法律分类依据
①按制作主体的不同,可分为:侦查文书、检察文书、诉讼文书、公证文书、仲裁文书、律师实务文书;
②以写作和表达方法的不同,可分为文字叙述式文书、填空式文书、表格式文书和笔录式文书
③按文种的不同,可分为报告类文书、通知类文书、判决类文书、裁定类文书、决定类文书等。
一、民事诉讼类:起诉状、反诉书、答辩状、代理词、刑事附带民事起诉书、上诉状、强制执行申请书、财产保全申请书、先予执行申请书、回避申请书、宣告失踪申请书、宣告死亡申请书、支付令申请书、再审申诉书;
二、婚姻家庭类:婚前财产协议书、离婚协议书、抚养子女协议书、遗赠协议书、遗赠抚养协议书、收养协议书;
三、公司类:各类公司合同、股权转让协议、法律意见书、律师工作报告、各类规章制度、公司章程、规章制度、人事管理办法、劳动管理办法、资产管理办法等;
四、劳动类:劳动合同书、劳务合同书、劳动仲裁申诉书:
四、刑事诉讼类:控告状、刑事自诉状、取保候审申请书、上诉书、再审申诉书;
五、行政类:行政复议申请书、行政诉讼起诉书、行政诉讼答辩书、行政强制执行申请书、行政上诉书、行政再审申诉书;
六、经济类:买卖合同、转让合同、借款合同、承揽合同、承包合同、运输合同、租赁合同、赠与合同、经营合同、合伙协议等;




